

This post offer a comprehensive overview of Apache Kafka, a powerful distributed streaming platform designed for high-throughput and fault-tolerant real-time data processing. Key topics include Kafka's architecture, components like topics, producers, consumers, and brokers, along with advanced features such as Kafka Streams for stream processing, data retention, and Kafka Connect for system integration. Additionally, the notes cover schema management with Avro and the Schema Registry, emphasizing the significance of schema evolution. Practical examples, including Kafka's integration with PySpark, demonstrate the platform's capabilities in real-world applications, providing a solid foundation for leveraging Kafka in building scalable, real-time data processing systems.
Source:
Content:
Kafka structure
Apache Kafka is a distributed streaming platform that lets you publish and subscribe to streams of records, store streams of records in a fault-tolerant way, and process streams of records as they occur. Kafka is designed to handle high-volume data streams from multiple sources and distribute them to multiple consumers efficiently.

Events and messages
In Apache Kafka, events are records or messages that represent facts or occurrences in a system. An event contains data that is transmitted from a producer (the source of data) to a Kafka cluster. Messages in Kafka are essentially the same as events; they contain information to be stored in topics and consist of a key (optional), a value, and metadata like a timestamp. Kafka stores and processes these messages/events in a fault-tolerant and scalable manner, allowing consumers to read them asynchronously.
Topics
Description: A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
Structure: Topics are divided into partitions, where each partition is an ordered, immutable sequence of records that is continually appended to—a commit log. Each record in a partition is assigned and identified by its unique offset.
Partitions
A partition is assigned to one consumer only.
One consumer may have multiple partitions assigned to it.
If a consumer dies, the partition is reassigned to another consumer.
Ideally there should be as many partitions as consumers in the consumer group.
If there are more partitions than consumers, some consumers will receive messages from multiple partitions.
If there are more consumers than partitions, the extra consumers will be idle with nothing to do.
Messages in a topic are distributed to partitions based on their keys by hashing the key and then using the hash value modulo the number of partitions to determine the partition. This ensures messages with the same key go to the same partition, maintaining their order. Although this method could lead to uneven partition sizes—if one key is much more active—it is generally not a concern, and the advantages of preserving message order outweigh the potential for imbalance.
Producers
Description: Producers are applications or processes that publish (write) data records to Kafka topics. Producers decide which record to assign to which partition within a topic.
Structure: Typically, a producer will round-robin records to partitions unless a specific partition is specified, or some partitioning logic is implemented based on keys within the record.

Acknowledgments (acks) control message durability during publishing. They range from
acks=0for no wait and highest throughput but lowest durability, toacks=1for waiting on the leader broker, offering a balance, andacks=allfor waiting on all replicas, ensuring highest durability. This allows producers to choose between throughput and message safety.
Consumers
Description: Consumers read data from topics. Consumers subscribe to one or more topics and process the stream of records produced to them.
Structure: Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.

Brokers
Description: Kafka brokers are servers that store data and serve clients. A Kafka cluster is composed of multiple brokers to maintain load balance.
Structure: Brokers contain topic log partitions. They handle all read and write requests for their partitions. Data is replicated across multiple brokers for fault tolerance.
ZooKeeper
Description: ZooKeeper is used by Kafka to manage and coordinate the Kafka brokers. Kafka uses ZooKeeper to elect leaders among the brokers, manage service discovery for Kafka brokers, and for configuration management.
Note: Kafka versions 2.8 and later introduced KRaft mode, aiming to remove the dependency on ZooKeeper. However, ZooKeeper is still widely used in many Kafka deployments.
Replication
Description: Kafka replicates the log for each topic's partitions across a configurable number of servers. This is how Kafka achieves fault tolerance. If a broker fails, other brokers will take over the work by using the replicas.
Kafka Streams
Description: Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It allows for stateful and stateless processing of stream data.
Retention
In Apache Kafka, retention refers to the policy that determines how long messages are stored in a topic before being deleted. Retention can be based on time (
retention.ms), which specifies how long messages are kept, or on size (retention.bytes), which limits the total size of messages retained in a topic. Additionally, Kafka offers log compaction (cleanup.policy), which retains only the latest message for each key, useful for maintaining the most current state of data. These settings help manage disk space and ensure data availability according to specific requirements.
Kafka Connect
Description: Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. It makes it simple to quickly define connectors that move large collections of data into and out of Kafka.

Offsets
Offsets (
__consumer_offsets): Kafka stores messages in the partitions in an immutable sequence. Each message within a partition has a unique identifier called an offset. Consumers track their position (offset) in each partition to know which messages have been consumed and which have not.
Kafka Installation
For Kafka installation instructions, refer to the official website. Managing Kafka manually can be complex, so we recommend using a docker-compose script, available via this link, courtesy of Confluent, a provider of Kafka tools. The script sets up several services:
Zookeeper: Essential for managing Kafka's configuration information, like topic partitions. Although Kafka is moving away from Zookeeper, it simplifies setup in this context.
Broker: Kafka's core service, configurable via many environment variables. This service includes both Kafka and Confluent Server, which adds commercial features to Kafka.
Kafka-tools: Offers additional tools from the Confluent Community, to be explored later in this lesson.
Schema-registry: Manages metadata serving, a component we'll utilize further in the lesson.
Control-center: A web interface for Kafka, enhancing visualization despite Kafka's command-line operability.
To begin, download the script to your working directory and launch it with docker-compose up. Initial deployment might take a few minutes. Verify the status with docker ps. Once deployed, access the control center GUI by navigating to localhost:9021.
Avro and Schema Registry
Schemas are crucial in Kafka to ensure data compatibility across different producers and consumers. Since Kafka messages can vary widely in format, from plain text to binary, schemas help define the structure of the data being exchanged, preventing issues where consumers cannot interpret the messages due to format incompatibilities.
Avro
Avro Overview: Avro is a serialization system that separates the schema from the data, unlike Protobuf or JSON. It requires an Avro schema to interpret records.
Encoding & Schemas: Uses binary encoding for data and JSON or IDL for schema definition.
Advantages:
Reduced file size compared to formats like JSON.
Enables schema evolution, allowing changes over time without breaking consumers.
Avro clients provide automatic schema validation, blocking incompatible changes.
Kafka Support: Avro is fully supported by Kafka, enhancing data compatibility and consistency.
Schema Compatibility:
Implicit schemas in formats like JSON can lead to consumer confusion with schema changes.
A schema registry helps maintain a contract between producers and consumers by validating and updating schemas automatically.
Schema Evolution Types:
Backward Compatibility: Older schemas can produce messages readable by consumers with newer schemas.
Forward Compatibility: Newer schemas produce messages that are readable by consumers with older schemas.
Mixed/Hybrid Versions: Ideal state where schemas are both forward and backward compatible, ensuring all consumers can read all records.

Temaplate of avsc schema file:
{ "type": "record", "name": "YourRecordName", "namespace": "your.namespace", "fields": [ { "name": "field1", "type": "type1", "doc": "Description of field1" }, { "name": "field2", "type": "type2", "doc": "Description of field2" }, { "name": "field3", "type": ["null", "type3"], "default": null, "doc": "Description of field3" } // Add more fields as needed ] }
Schema registry
The Schema Registry is a key component in Kafka ecosystems for managing schema definitions and ensuring compatibility between producers and consumers. Here's how it works:
Workflow with Kafka:
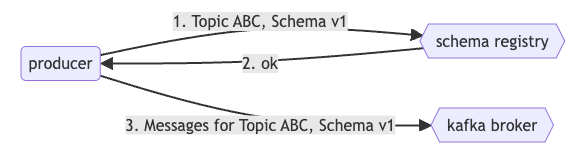
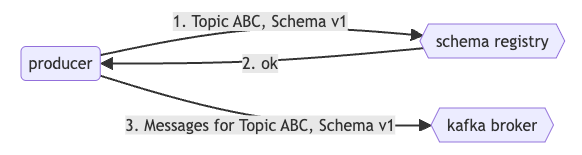
Producer Registration: A producer planning to publish messages to topic ABC with schema v1 checks with the schema registry first.
Schema Validation:
If the schema for the topic doesn't exist, the registry registers v1 and approves the producer's request.
If a schema exists, the registry checks compatibility with both the producer's schema and the registered schemas.
Compatibility Check:
Success: The registry approves, and the producer begins posting messages using schema v1.
Failure: The registry rejects the schema as incompatible, and the producer encounters an error.
Consumer Subscription: When a consumer aims to read from topic ABC, it consults the schema registry to determine the appropriate schema version, accommodating scenarios with multiple compatible schema versions.
Handling Incompatible Schemas:
When schema updates result in incompatibility, the recommended approach is to:
Introduce a new topic for the updated schema.
Implement a service to translate messages from the new schema back to the old schema, allowing gradual migration to the new topic by services.
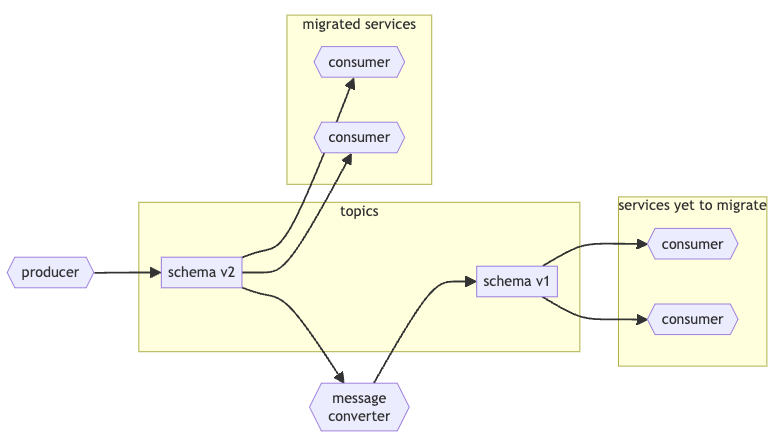
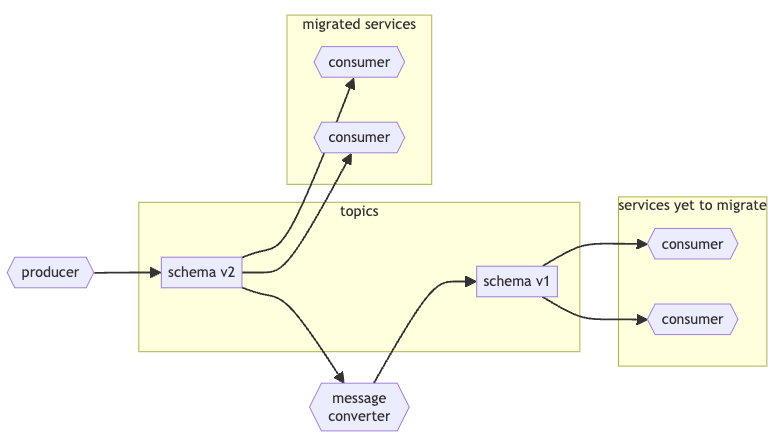
This structure maintains data integrity and compatibility across a distributed system, enabling flexible schema evolution while minimizing disruptions.
Demo: Schema Evolution with Avro
Schema Definitions
Using JSON syntax, we define two schemas and save them as .avsc files: one for the message key and another for the message value.
Message Key Schema: Identifies the message with basic information. The schema is detailed in taxi_ride_key.avsc. It contains a single field,
vendorId, of typeint.Message Value Schema: Outlines the structure of the message content. The taxi_ride_value.avsc file includes several primitive data types. This schema corresponds with data found in the rides.csv
Producer Implementation
We create a producer.py script to:
Import necessary libraries from
confluent_kafka.Define a function to load both schema files.
Within the
send_record()method:Specify Kafka broker and schema registry URLs, alongside the acknowledgment policy.
Initialize an
AvroProducer.Read data from a CSV file, constructing key-value dictionaries for each row.
Use
AvroProducer.produce()to send Avro-serialized messages to the Kafka topicdatatalkclub.yellow_taxi_rides.Handle exceptions for failed message sends, print success notifications, and regulate message flow with
flush()andsleep()for pacing.
Consumer Implementation
We also devise a consumer.py script to:
Import
AvroConsumerfromconfluent_kafka.avro.Set consumer configurations, including URLs, group ID, and offset reset policy.
Instantiate
AvroConsumerand subscribe to the topic.Continuously poll for messages every 5 milliseconds, printing and committing each found message.
Running the Demo
Execute
producer.py, thenconsumer.pyin a separate terminal. Messages, formatted according to our defined schema, will appear in the consumer's output. Stop the scripts afterward.Alter
taxi_ride_value.avsc, changing a data type (e.g.,total_amountfrom float to string), and save the changes.Rerunning
producer.pywill lead to errors due to schema incompatibility. Initially, the topic was associated with a specific schema in the registry. Altering the schema without updating consumer expectations causes a mismatch, as the registry detects the incompatibility when the producer attempts to send messages under the modified schema.
Kafka Streams
Introduction to Kafka Streams
Kafka Streams is a library for building data processing applications within Kafka clusters, enabling real-time processing by reading from and writing to Kafka topics. It's scalable, fault-tolerant, and offers a Domain Specific Language (DSL) for easier development. While simpler than Spark or Flink, it's specifically designed for Kafka and may not suit applications requiring data from multiple sources.
Understanding Streams and State
In streaming data processing, distinguishing between "Streams" (or KStreams) and "State" (or KTable) is crucial:
Streams (KStreams) represent sequences of individual messages processed one after the other.
State (KTable) acts as a snapshot or changelog of a stream at a certain moment, essentially providing a current state view of the stream data, and is also stored as topics in Kafka.


Global KTable
A Global KTable functions similarly to a broadcast variable, with all its partitions replicated across every Kafka instance. This feature facilitates easier and more efficient joins without the necessity for data co-partitioning. However, the trade-offs include higher local storage requirements and increased network traffic. Consequently, Global KTables are best suited for managing smaller datasets.


Topologies and Features in Kafka Streams
A topology, essentially the processor topology, outlines the data transformation logic from input to output within an application. It's depicted as a graph where stream processors (nodes) are interconnected by data streams (edges). This abstraction aids in designing and conceptualizing streaming applications.
Stream processors, which represent data transformation steps like mapping, filtering, joining, or aggregating, can be defined using either the imperative Processor API or the declarative DSL, with this discussion focusing on the DSL.
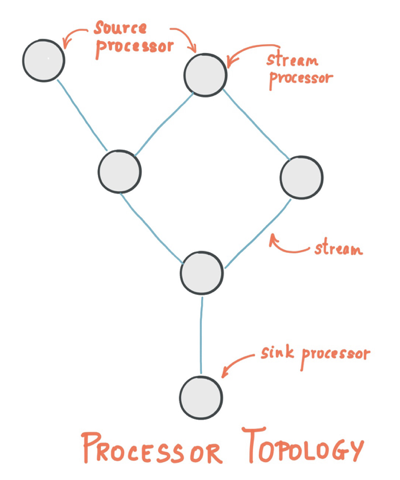
Kafka Streams enriches processing capabilities with features like:
Aggregations (count, groupBy)
Stateful Processing (internally managed within Kafka topics)
Joins (between KStream-KStream, KStream-KTable, and KTable-KTable)
Windows (time-based, session-based), facilitating stateful operations by grouping records with the same key.
Demo: Kafka Streams
Instead of Scala, we use Python and the Faust library for Kafka Streams applications for ease and flexibility.
Consumer template using Faust
import faust
# Initialize the Faust application
app = faust.App(
'your_app_name',
broker='kafka://your_kafka_broker_address',
consumer_auto_offset_reset="earliest"
)
# Define the Kafka topic and the value type (model) to use for messages
topic = app.topic(
'your_kafka_topic_name',
value_type=YourCustomModel
)
# Example of a Faust agent to process messages from the topic
@app.agent(topic)
async def process(stream):
async for event in stream:
# Process each event here
print(f"Processing event: {event}")
if __name__ == '__main__':
app.main()In the control center (localhost:9021) create following topics:
datatalkclub.yellow_taxi_ride.json
datatalks.yellow_taxi_rides.high_amount
datatalks.yellow_taxi_rides.low_amount
Sends JSON messages from a CSV file to
datatalkclub.yellow_taxi_ride.jsonat one message per second.Run
python producer_tax_json.py
Initializes a Faust app, subscribes to the
datatalkclub.yellow_taxi_ride.jsontopic, and prints each message using the customTaxiRideclass for data.Run
python stream.py worker
Similar setup, but uses
app.Table()for stateful count of messages byvendorId.Run
python stream_count_vendor_trips.py worker
Sorts messages into high or low amount topics based on a threshold.
Run
python branch_price.py worker
Joins in Streams
Streams support various types of joins:
Outer
Inner
Left
Joins can occur between different combinations of streams and tables:
Stream-to-stream join: This type is always windowed, meaning you must define a specific timeframe for the join.
Table-to-table join: This type is never windowed, operating directly on the table contents.
Stream-to-table join: This type allows for flexibility in combining real-time and historical data.
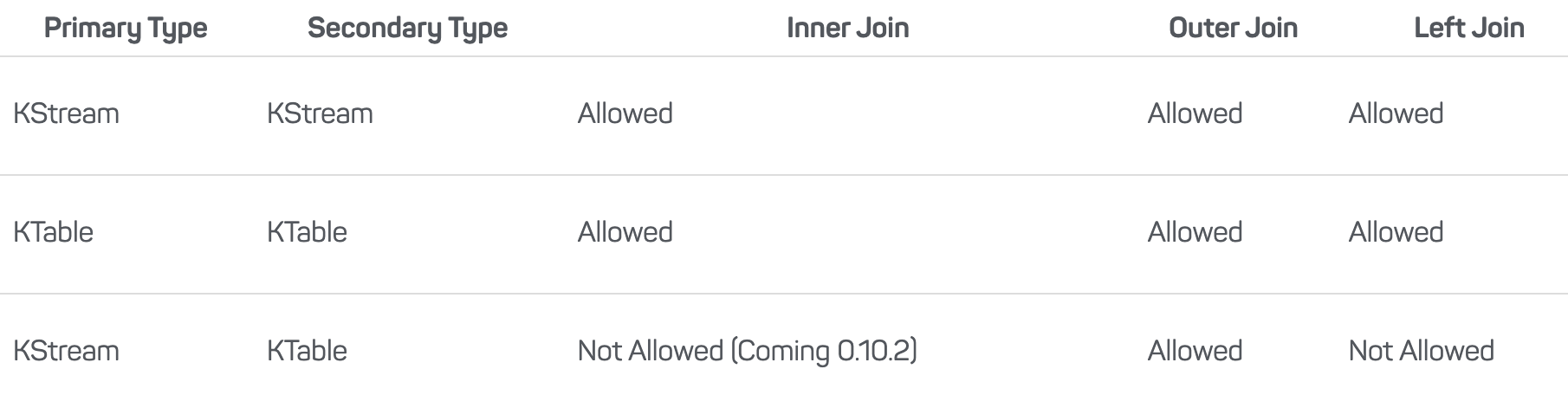
For more details on their behavior, refer to the official documentation.
The key distinction is that stream-to-stream joins are windowed, meaning they occur within a specified "temporal state" of the streams. In contrast, table-to-table joins are not windowed and are based on the actual data present in the tables at the time of the join.
Timestamps
Kafka messages include timestamps to facilitate time-based processing in Kafka Streams:
Event Time: The time the event occurred, embedded within the message.
Processing Time: The time the event is processed by the stream processor.
Ingestion Time: The time the event is received by the Kafka broker.
These timestamps support operations like joins and windowing, allowing for flexible stream processing strategies.
Windows in Streams
Windowing in Kafka Streams is a method to group events within specific time frames. It's essential for operations that need to analyze data within defined time boundaries. There are two primary types of windows:
Time-based Windows: These are based on chronological time.
Fixed/Tumbling Windows: Each window has a set duration and doesn't overlap with others. Windows follow sequentially, one after another.
Sliding Windows: Similar in having a set duration, but they allow for overlapping, meaning multiple windows can be active concurrently, each starting at successive time intervals.
Session-based Windows: These group events by activity sessions rather than fixed time. A session window begins with an event for a specific key and closes when there's no activity for that key. Different sessions for various keys can occur simultaneously.
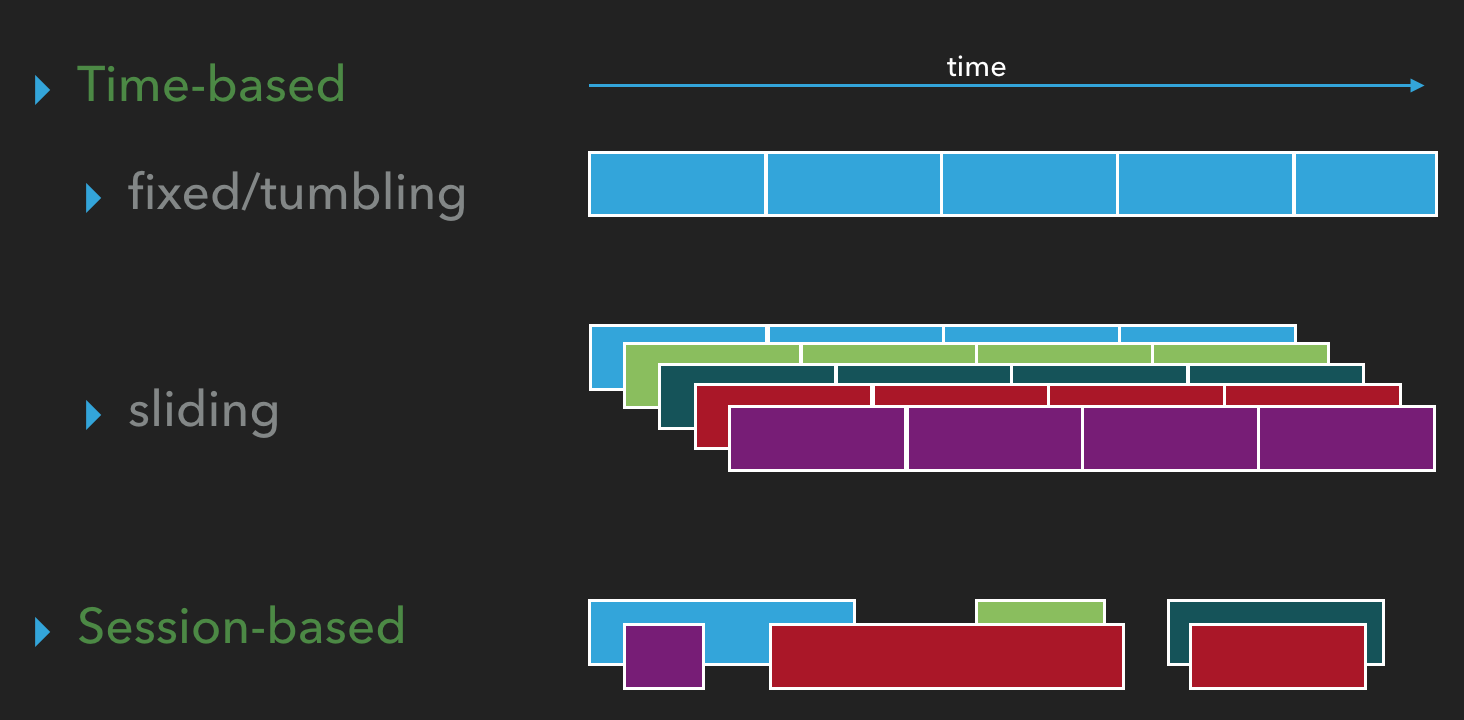
Demo: Kafka streams - windows
The script counts messages using a one-minute tumbling window, where each key in the Control Center represents a window along with its time interval and message count. It features a windowed table to count rides per vendor, resetting every minute and expiring after an hour to manage memory.
Launch the script
python windowing.py workerksqlDB
ksqlDB is a streaming SQL engine that enables real-time data processing against Apache Kafka®. It provides an easy-to-use yet powerful interactive SQL interface for stream processing, allowing you to build real-time applications without needing to write complex code in a programming language such as Java or Python.
With ksqlDB, you can create streams and tables over Kafka topics, run continuous queries, and perform stream processing tasks like filtering, transformations, aggregations, and joins.
Key Concepts
Stream: A stream in ksqlDB is a sequence of immutable data records, similar to a Kafka topic, where each record represents an event.
Table: A table in ksqlDB represents the latest value for each key, similar to a traditional database table but dynamic and updating in real-time as new events arrive.
Query: ksqlDB uses SQL-like queries to process data in streams and tables, enabling complex stream processing operations with simple SQL commands.
Kafka connect
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. It's part of the Apache Kafka project and provides a framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems. Using Kafka Connect, you can import data from external systems into Kafka topics and export data from Kafka topics into external systems.
Key Concepts
Connector: A reusable component that implements the logic for interacting with a specific type of external system. Connectors come in two flavors:
Source Connectors: Import data from external systems into Kafka.
Sink Connectors: Export data from Kafka to external systems.
Task: The actual unit of work. A single connector might split its work into multiple tasks, which can be distributed across a cluster for scalability and fault tolerance.
Worker: The process ru nning the connector and task instances. Workers can be standalone (for development and testing) or distributed (for scalability and fault tolerance in production).
Kafka & PySpark
Understanding PySpark and Kafka
Apache Spark is an open-source, distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Spark supports batch processing, real-time streaming, machine learning, and graph processing. When using Spark for real-time stream processing, it's often referred to as Spark Streaming.
Apache Kafka is a distributed streaming platform that lets you publish and subscribe to streams of records, similar to a message queue or enterprise messaging system. Kafka is designed for fault tolerance, high throughput, scalability, and durability. It's often used as the backbone for streaming data pipelines and applications that require real-time data processing.
How They Work Together
Publish/Subscribe Model: Kafka acts as the messaging system or the stream platform that handles the real-time data feeds. Spark Streaming (PySpark) can subscribe to one or more Kafka topics to read data streams and process them.
DStream and Structured Streaming: Spark Streaming provides two main abstractions for streaming data - DStream and Structured Streaming. DStreams are a series of RDDs (Resilient Distributed Datasets), whereas Structured Streaming provides a higher-level API built on Spark SQL to work with streaming data as if you were working with a static DataFrame.
Fault Tolerance: Both Kafka and Spark Streaming are designed to handle failures gracefully, ensuring that your streaming applications continue to run without data loss.
Basic Example
Let's go through a simple example where PySpark reads from a Kafka topic, processes the data, and then writes the results back to another Kafka topic.
Requirements
Apache Spark with the Kafka package (use
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.2when launching PySpark if not already included)Apache Kafka (with Zookeeper if using Kafka versions < 2.8.0)
Steps
Kafka Setup: Assume you have Kafka running and a topic named
input-topicto read from and anoutput-topicto write to.Reading from Kafka:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("PySpark Kafka Example") \
.getOrCreate()
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "input-topic") \
.load()Data Processing: Let's say you just want to uppercase the text from the input stream (assuming the messages are text).
from pyspark.sql.functions import col, upper
# Assuming the value column in the Kafka record is of type string
processed_df = df \
.select(upper(col("value") \
.cast("string")) \
.alias("value"))Writing to Kafka:
query = processed_df \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("topic", "output-topic") \
.option("checkpointLocation", "/path/to/checkpoint/dir") \
.start()
query.awaitTermination()This example provides a basic setup. Real-world applications may involve more complex transformations, aggregations, windowing operations, and integration with other data sources or services.
Remember to handle serialization and deserialization of Kafka messages, as Kafka deals with byte arrays. The value in Kafka records is often serialized JSON, Avro, or another format that you'll need to deserialize for processing and then serialize again for writing back to Kafka or another sink.
Demo: Pyspark structured streaming
In this example (link), we'll be setting up a basic producer to interact with the Spark streaming service, as detailed in the streaming.py script.
The streaming script file demonstrates the following workflow:
Spark Session Initialization
Spark Session: The entry point for programming Spark applications. It's created at the beginning and used throughout for reading from and writing to Kafka, and for query execution.
Functions Defined
read_from_kafka: Reads streaming data from a specified Kafka topic. It uses thereadStreammethod to create a streaming DataFrame by subscribing to a topic.parse_ride_from_kafka_message: Parses each message from Kafka based on a predefined schema. This function casts thekeyandvaluefrom Kafka's binary format to strings, splits thevaluestring into an array based on a delimiter, and then maps each element of the array to a column in the DataFrame according to the provided schema.sink_console: Outputs the streaming DataFrame to the console. This is useful for debugging or monitoring the data transformation in development environments.sink_memory(not utilized in the main logic): Intended for sinking the streaming DataFrame into in-memory storage, which can be queried using Spark SQL. However, this function is defined but not used in the main application flow.sink_kafka: Writes the processed streaming data back into a Kafka topic. This allows for the results of the stream processing to be consumed by other applications or stored for further processing.prepare_df_to_kafka_sink: Prepares a DataFrame for writing back to Kafka by concatenating specified columns into a singlevaluecolumn, optionally renaming a column tokey, and casting thekeyto a string. The resulting DataFrame consists only ofkeyandvaluecolumns.op_groupby: Performs a simple group-by operation on the DataFrame based on the specified column names and counts the occurrences.op_windowed_groupby: Similar toop_groupby, but it applies a windowing function to group the data based on time windows and counts the occurrences for each window.
Main Logic
The script initializes a Spark session and sets the log level to
WARNto reduce verbosity.It reads streaming data from a Kafka topic specified by
CONSUME_TOPIC_RIDES_CSV.It parses the Kafka messages according to a schema defined by
RIDE_SCHEMA.The parsed data is then processed using group-by operations, both with and without windowing.
The results are prepared for Kafka and written back to a new topic defined by
TOPIC_WINDOWED_VENDOR_ID_COUNT.Finally, the script waits for any of the streaming queries to terminate.
Key Concepts Illustrated
Consuming and producing data with Kafka in a streaming context with Spark.
Processing streaming data with basic transformations and windowing functions.
Dynamic handling of streaming data schema.
Use of various output sinks (console, Kafka) for streaming data.