

Explore the fundamentals and advanced strategies in data management and modeling with this concise guide. Covering everything from data infrastructure and storage to sophisticated modeling techniques and the Medallion Architecture, it provides a solid foundation for understanding and applying data management principles in a modern data-driven environment. Whether you're dealing with Dimensional Modeling or exploring Data Vault and Anchor Modeling, this guide is your key to navigating the complexities of today's data landscapes.
Contents:
Data management infrastructure
Data Processing Systems
OLAP (Online Analytical Processing) and OLTP (Online Transaction Processing) are two types of data processing systems that are used for different purposes in the world of database management and data warehousing.
The main difference between OLAP and OLTP systems lies in their primary functions and the types of queries they handle. OLAP is focused on complex queries for analytical purposes, working with historical data to help in decision-making processes. On the other hand, OLTP is designed to efficiently process a large number of transactions, focusing on the speed and reliability of operational tasks.

Data storage
Databases
Definition: A structured collection of data stored electronically, designed for efficient insertion, querying, updating, and management of data.
Examples: MySQL, PostgreSQL (OLTP); Oracle Exadata (supports both OLTP and OLAP).
Use case: Supporting application-specific data storage, real-time transaction processing, customer management, inventory tracking.
Advantages: Efficient data management and retrieval, transactional integrity, supports complex queries with structured schemas.
Limitations: May not handle very large volumes of unstructured data well, scalability can be challenging, especially for write-heavy workloads.
Related to: Primarily OLTP, though some databases are designed to support OLAP functionalities as well.
DWH (Data Warehouse)
Definition: A centralized repository optimized for analysis and querying of structured data from multiple sources, designed to support decision-making processes.
Examples: Amazon Redshift, Google BigQuery, Snowflake.
Use case: Business intelligence, reporting, historical data analysis, and complex querying across various data sources.
Advantages: Supports complex queries and analytics on large datasets, optimized for read-heavy operations, consolidates data from multiple sources.
Limitations: Less flexible in handling raw, unstructured data, can be expensive and complex to maintain and scale.
Related to: OLAP.

Data Lakes
Definition: A storage repository that can store vast amounts of raw, unstructured data in its native format until it is needed, supporting big data and analytics.
Examples: Amazon S3, Azure Data Lake Storage, Google Cloud Storage.
Use case: Storing raw, unstructured data for future processing and analysis, machine learning projects, and data discovery.
Advantages: Scalable storage solution, flexibility in handling all types of data, cost-effective for storing large volumes of data.
Limitations: Can become a "data swamp" if not managed properly, data governance and quality can be challenging.
Related to: Primarily used for OLAP purposes but can store data for any type of processing.
Data Lakehouses
Definition: An architectural approach that combines elements of data lakes and data warehouses, aiming to provide the scalability and flexibility of a data lake with the management features of a data warehouse.
Examples: Databricks, Delta Lake on Databricks, Apache Hudi, Apache Iceberg.
Use case: Unified analytics (data science, machine learning, and SQL analytics), real-time analytics, and providing a single source of truth for both structured and unstructured data.
Advantages: Supports both OLTP and OLAP workloads, provides robust data governance and quality, and efficiently handles diverse data types.
Limitations: Can be complex to implement and manage, requires a careful balance of flexibility and governance.
Related to: Designed to support both OLAP (for analytics) and OLTP (for transactional workloads) in a unified environment.
Related concepts
Data Marts
Description: A focused segment of a DWH designed to provide specific business groups with access to relevant data for reporting and analysis.
Example Products:
Microsoft SQL Server Reporting Services (SSRS): Often used to create and manage data marts for specific reporting needs within the Microsoft ecosystem.
IBM Db2 Warehouse: Offers capabilities to design and deploy data marts for various business departments.
Oracle Database: Provides features to build data marts within its database ecosystem, utilizing Oracle's advanced analytics and data management tools.
Use case: Ideal for department-specific analytics, such as sales performance metrics for a sales team or supply chain analytics for a logistics department.
Delta Lake
Description: Delta Lake is an open-source layer that enhances data lakes with ACID transactions, scalable metadata, and unified data processing, ensuring data integrity for analytics and transformations. It's key to developing data lakehouse architecture, merging data lakes' flexibility with the governance of data warehouses. This allows for both OLAP and OLTP workloads on a single platform, streamlining data analysis, reporting, and machine learning.
Example Products:
Databricks: Offers a managed Delta Lake as part of its platform, providing enhanced data reliability and performance for analytics.
Azure Databricks: Provides Delta Lake on a collaborative Apache Spark-based analytics platform, facilitating advanced data management and analytics.
Use case: Delta Lake is instrumental for organizations aiming to improve their data lakes with better data governance, transactional integrity, and to support complex ETL processes across both real-time and batch data.
Data storage format (row vs column)
Data storage formats, namely row-based and column-based, determine how data is organized and stored within a database or data storage system.
Row-based format: In row-based storage, data is stored and retrieved one row at a time. This means that all columns of a single row are stored together, making it efficient for operations that involve accessing entire rows of data. It's typically used in transactional databases where individual records are frequently updated or inserted.
Column-based format: In column-based storage, data is stored and retrieved one column at a time. This means that all values for a particular column are stored together, making it efficient for operations that involve aggregations, analytics, or queries that access specific columns of data. It's commonly used in analytical databases or data warehouses where queries often involve aggregating or analyzing large datasets.

Data serialization formats
Data serialization formats efficiently convert data structures into a suitable format for storage, transmission, or reconstruction. They possess key properties:
Efficiency: Minimizing size and processing overhead.
Interoperability: Language and platform independence.
Flexibility: Supporting diverse data types and schema evolution.
Human Readability: Offering readability for easier debugging.
Schema Support: Enabling validation, versioning, and consistency.
Binary Representation: Providing compact storage and bandwidth efficiency.
Extensibility: Allowing for future adaptation without breaking compatibility.
These properties facilitate efficient and interoperable data exchange, storage, and communication across various systems and environments.
Common examples include:
Parquet
Parquet is a columnar storage format optimized for distributed processing frameworks like Apache Hadoop and Apache Spark. It organizes data by columns rather than rows, which improves compression and query performance, especially for analytics and reporting workloads.
ORC (Optimized Row Columnar)
ORC is another columnar storage format designed for efficient storage and processing of large datasets in Hadoop-based environments. It provides advanced compression techniques and supports complex data types and schema evolution, making it suitable for data warehousing and analytics.
Avro
Avro is a data serialization format that offers compact, fast, and binary data representation with support for schema evolution. It's commonly used in messaging systems like Apache Kafka and for inter-process communication where efficiency and flexibility are important.
CSV (Comma-Separated Values)
CSV is a simple text-based file format used for storing tabular data with values separated by commas or other delimiters. It's widely supported and easy to work with, making it suitable for data interchange, importing/exporting data, and spreadsheet data.
JSON (JavaScript Object Notation)
JSON is a lightweight, human-readable data interchange format commonly used in web APIs, configuration files, and NoSQL databases. It supports nested and flexible data structures, making it suitable for data interchange between different systems.
Excel
Excel is a proprietary spreadsheet application by Microsoft, storing data in a binary format within workbook files (e.g., .xlsx). It provides rich features for data analysis, reporting, and visualization, but the binary format may not be easily readable or manipulatable by other systems.
TXT (Plain Text)
TXT files are plain text files containing unformatted text, versatile and can be opened with any text editor. They lack support for structured data and advanced features available in other formats but are simple and widely supported for basic data storage and exchange purposes.
XML (Extensible Markup Language):
Description: XML is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. It is commonly used for representing structured data in a hierarchical format, with tags defining the structure and content of the data. XML is widely adopted for data interchange, configuration files, and web services due to its flexibility and self-describing nature. However, XML can be verbose and may result in larger file sizes compared to more compact binary formats like JSON or Avro.

Data integration (ETL vs ELT)
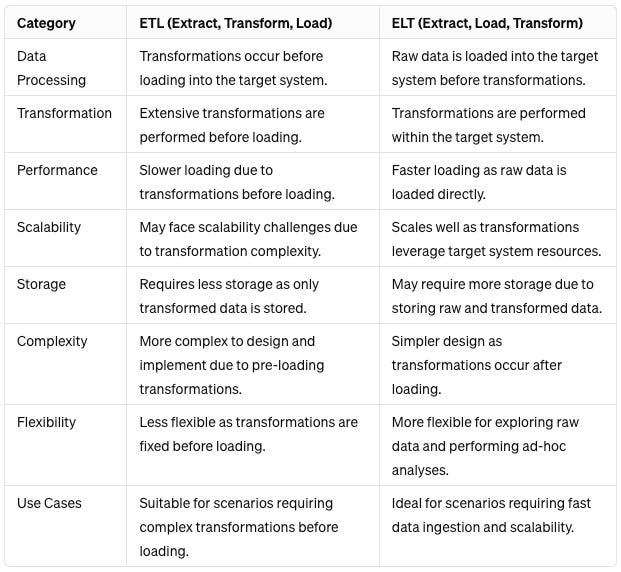
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two data integration approaches for moving data from source to target systems:
ETL:
Extract: Data is fetched from various sources without significant modifications.
Transform: Data undergoes cleansing, enrichment, and restructuring before loading.
Load: Transformed data is loaded into the target system, ensuring efficient storage.
Advantages:
Separation of concerns simplifies maintenance.
Optimizes performance through pre-loading transformations.
Ensures data quality through cleansing and validation.
Disadvantages:
Longer processing times due to pre-loading transformations.
Complexity in design and implementation, requiring specialized skills.
ELT:
Extract: Raw data is extracted from sources without extensive transformation.
Load: Raw data is loaded directly into the target system for faster ingestion.
Transform: Transformation processes occur within the target environment.
Advantages:
Scalable for handling large volumes of data.
Provides faster insights for analytics and reporting.
Offers flexibility in data exploration and analysis.
Disadvantages:
Increased storage requirements for storing raw data.
Complexity in transformations may require specialized tools and skills.
Comparison:
ETL focuses on transforming data before loading, while ELT loads raw data first and transforms afterward.
ETL may offer better performance for complex transformations, while ELT provides faster data loading and scalability.
ETL requires less storage since only transformed data is stored, whereas ELT may need more storage for raw and transformed data.
ETL processes are more complex to design, while ELT processes are simpler but may require expertise in the target environment.
Ultimately, the choice between ETL and ELT depends on specific requirements, source/target system characteristics, and desired outcomes. Organizations may opt for a hybrid approach based on their needs.
DWH Modeling
Data Warehouse (DWH) modeling is the design process for structuring a data warehouse to efficiently store, manage, and retrieve data for analysis and reporting.
It involves organizing data into tables with defined relationships to support business intelligence activities like reporting and decision-making.
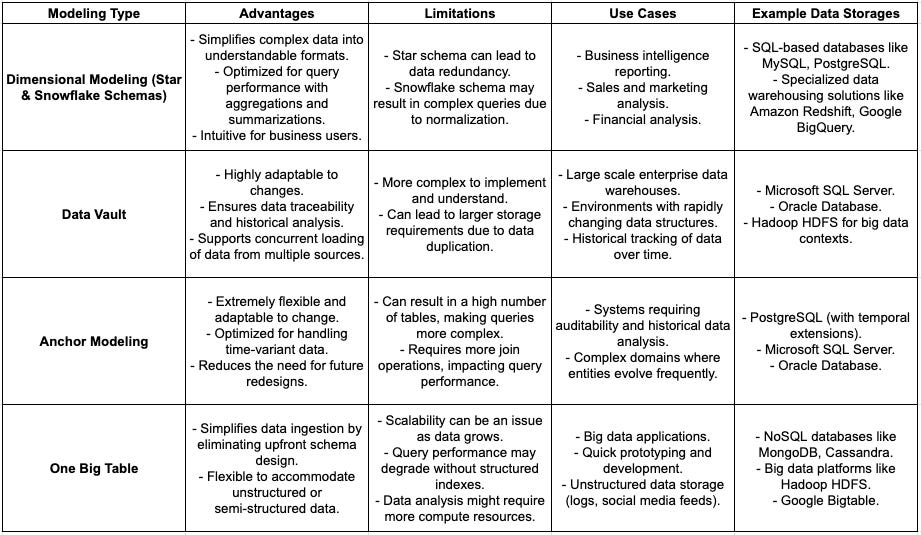
Dimensional Modeling (Kimball Approach)
Dimensional Modeling is a design technique used for data warehouses that is aimed at making databases understandable and fast. The approach organizes data into two types of tables: facts and dimensions.
Fact Tables: These tables contain the measurements, metrics, or facts of a business process. An example would be sales transactions in a retail business, where each transaction would capture data like the number of units sold and the dollars exchanged.
Dimension Tables: These tables contain descriptive attributes related to fact data to provide context. For example, a Product dimension table might include details such as product name, category, and price.
Dimensional modeling structures data into a specific format that is intuitive for business users and optimized for query performance. There are two primary schemas in dimensional modeling:
Star Schema: In a star schema, a single, central fact table connects to multiple dimension tables. It's called a "star schema" because the diagram resembles a star with a fact table at the center and dimension tables radiating outwards. This model simplifies queries and is generally easier to understand.
Snowflake Schema: The snowflake schema is a variation of the star schema where dimension tables are normalized into multiple related tables. This reduces data redundancy but can make queries more complex because it requires more joins.
Data Vault Modeling
Data Vault is a modeling approach designed to provide long-term historical storage of data coming from multiple operational systems. It is also aimed at providing a method for looking at historical data that deals with issues such as scalability, adaptability, and traceability.
Hub Tables: Store unique list of business keys.
Link Tables: Store relationships between hubs and can also link other links.
Satellite Tables: Store descriptive information (attributes) about the hubs and links, capturing the changes over time.
Data Vault is particularly useful in environments where data is changing rapidly, and the business needs a robust method to capture historical changes.

Anchor Modeling
Anchor Modeling is an approach to database design that aims to handle time-variant data in a highly flexible way. It's a technique that uses a single anchor table for each distinct entity and allows for versioning of every piece of information.
Anchor Tables: Represent entities.
Attribute Tables: Store attributes for entities in anchor tables.
Tie Tables: Represent relationships between entities.
This model excels in environments where the database schema must adapt to changes in data requirements without significant rework.
One Big Table Approach
The One Big Table approach, while not a formal modeling technique like the others, refers to a simplified way of storing data in a single, large table. This is often used in specific contexts, such as with certain types of NoSQL databases or in big data applications where the schema-on-read capability is preferred over traditional relational schema-on-write models.
Simplicity: All data is stored in a single table, making it straightforward to dump data without worrying about schema design.
Flexibility: Ideal for unstructured data or when the data structure is not known in advance.
However, this approach can lead to challenges in querying and analyzing data efficiently as the volume grows and as data relationships become more complex.
Conclusion
Each of these models offers distinct advantages and is suited to particular types of business requirements and data management scenarios.
Dimensional modeling is widely used for its simplicity and efficiency in query performance, making it a staple in data warehousing.
In contrast, Data Vault and Anchor Modeling offer more flexibility and robustness for complex, changing data environments.
The One Big Table approach provides maximum simplicity and flexibility but at the cost of performance and complexity in data management and analysis.
Ensemble modeling
Ensemble modeling in the context of Data Warehousing (DWH) and Business Intelligence (BI) is an advanced approach that combines multiple data modeling techniques to harness their strengths and mitigate their weaknesses. Unlike traditional methods that rely on a single modeling technique (e.g., dimensional modeling, normalized modeling), ensemble modeling integrates different methodologies to create a more flexible, scalable, and comprehensive data warehouse architecture. This approach is particularly useful in complex data environments where no single modeling technique addresses all the data management and analytical requirements.
Key Components of Ensemble Modeling
Ensemble modeling might include, but is not limited to, the following components:
Dimensional Modeling: For user-friendly data access and fast query performance, especially suitable for reporting and business intelligence.
Data Vault Modeling: For capturing data from multiple sources in a detailed, auditable, and historically accurate manner, ensuring data integrity and flexibility.
Anchor Modeling: For efficiently managing and querying historical data changes over time, providing agility in handling schema evolution.
Advantages
Flexibility: By combining different methodologies, ensemble modeling can adapt to various business needs and data types.
Scalability: It supports the growth of data volume and complexity without significant redesigns of the data warehouse.
Comprehensiveness: Offers a more holistic view of the data, accommodating historical, real-time, structured, and unstructured data.
Robustness: Enhances data integrity, auditability, and the ability to track historical changes.
Use Cases
Ensemble modeling is particularly beneficial in scenarios where the data environment is complex, involving rapidly changing data from diverse sources, or when the requirements for data analysis and reporting are varied and evolve over time. It's also suitable for organizations that need to maintain a high level of data accuracy and traceability while ensuring that their data warehouse can adapt to future changes in data structures or business requirements.
Implementation
Implementing ensemble modeling requires a deep understanding of the available data modeling techniques and a strategic approach to selecting and combining those that best meet the organization's needs. It often involves iterative development and close collaboration between business analysts, data architects, and IT teams to ensure that the data warehouse architecture effectively supports business objectives.
In summary, ensemble modeling is a strategic approach to data warehouse design that leverages the strengths of multiple data modeling methodologies to create a more adaptable, scalable, and comprehensive data management solution.
Medallion Architecture
The Medallion Architecture, often discussed within the context of Data Engineering and Analytics, is a design framework used to structure and manage data within a data platform. It's known for categorizing data into three layers: Bronze, Silver, and Gold, each representing a different stage of data processing and refinement. This approach helps organizations structure their data lake or data warehouse to improve data management, quality, and accessibility for analytics and data science purposes. Let's break down each layer:
Bronze Layer (Raw Data Layer)
Description: This is the first layer of the Medallion Architecture, where all raw data is ingested into the data platform. Data in the Bronze layer is unprocessed and unfiltered, making it the most granular level of data available. It includes all forms of raw data, such as logs, CSV files, JSON documents, binary files, and more, often ingested from various sources like databases, applications, and external APIs.
Purpose: The primary goal of the Bronze layer is to capture and store data in its original form, ensuring that all information is retained for compliance, historical analysis, or further processing. It serves as an immutable historical record of the data as it was produced.
Management Practices: Data in the Bronze layer is usually partitioned and stored in a cost-effective, scalable storage solution (like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage) and managed using metadata to facilitate easier access and organization.
Silver Layer (Cleansed and Conformed Data Layer)
Description: The Silver layer is where raw data undergoes initial processing to become more usable. This processing might include cleansing (removing or correcting errors), deduplication, normalization, and transformation into a more analytics-friendly format. Data in this layer is more structured than in the Bronze layer and is often conformed to a common schema.
Purpose: The Silver layer aims to create a reliable and consistent data foundation for further analysis and insights. By cleaning and conforming the data, it ensures that downstream processes, like analytics and machine learning, can be performed more efficiently and accurately.
Management Practices: Data governance and quality control are crucial at this stage. Implementing practices like schema validation, quality checks, and maintaining a data catalog are common to ensure the integrity and usability of the data.
Gold Layer (Curated Data Layer)
Description: The Gold layer contains highly curated and enriched data that is ready for business intelligence, reporting, and advanced analytics. This data is often the result of joining, aggregating, or further processing Silver layer data to produce datasets directly aligned with business needs, such as KPI metrics, customer segments, and financial summaries.
Purpose: The aim of the Gold layer is to provide data that is directly actionable and supports decision-making processes. It is the most refined form of data in the architecture, tailored to specific business use cases and questions.
Management Practices: Data in the Gold layer is maintained with a focus on accessibility and performance. Efficient querying and data access patterns are prioritized, along with maintaining up-to-date and relevant data through regular updates and refreshes.
Conclusion
The Medallion Architecture enables a systematic approach to data processing and management, from raw ingestion to refined analytics-ready datasets. By segregating data into the Bronze, Silver, and Gold layers, organizations can manage their data lifecycle more effectively, ensuring data quality, compliance, and accessibility for a wide range of analytical and operational needs.
Outstanding work