
SQL interview questions

SQL (Structured Query Language) is vital for managing databases efficiently. This concise guide covers key SQL topics, from basics to optimization techniques. Explore database concepts, keys, indexes, functions, procedures, triggers, views, joins, set operators, command comparisons, schema design, and optimization. Whether refining skills or preparing for an interview, this guide equips you to navigate SQL confidently.
Contents:
Database Concepts
What is a database, DBMS, or RDBMS?
A database, DBMS (Database Management System), and RDBMS (Relational Database Management System) are related concepts but differ in their scope and functionality. Let's define each one:
Database
A database is a structured collection of data. It is a way to store and organize information in a manner that facilitates efficient access and management. Databases can store various types of data, such as text, numbers, multimedia, and more. They are crucial in numerous applications, from simple systems like contact management in phones to complex scenarios like data warehousing in large corporations.
DBMS (Database Management System)
A DBMS is a software tool or a suite of applications used to create, manage, and interact with databases. It provides users and programmers with a systematic way to create, retrieve, update, and manage data.
A DBMS ensures that the data is consistently organized and remains easily accessible. It also helps maintain the integrity and security of the data. Examples of DBMS include MySQL, PostgreSQL, Microsoft SQL Server, and Oracle.
Key functions of a DBMS include:
Data Definition: Creating, modifying, and deleting definitions that define the organization of the data.
Data Updating: Inserting, modifying, and deleting data.
Data Retrieval: Providing information in a format understandable to users.
User Administration: Managing user access permissions, enforcing data security, data integrity, and managing concurrency control.
RDBMS (Relational Database Management System)
An RDBMS is a specific type of DBMS that uses a relational model for its databases. This model is based on the concept of storing data in tables (also known as relations) which are linked to each other through relationships. Each table consists of rows (also known as records or tuples) and columns (attributes or fields).
RDBMS systems use Structured Query Language (SQL) for querying and maintaining the database. This type of system is the most common DBMS used today due to its flexibility and support for complex queries. Examples of RDBMS include Microsoft SQL Server, Oracle Database, MySQL, and PostgreSQL.
Key features of an RDBMS include:
Data Integrity: Ensuring accuracy and consistency of data over its lifecycle.
Normalization: Organizing data to reduce redundancy and improve data integrity.
ACID Properties: Ensuring atomicity, consistency, isolation, and durability of transactions.
Support for Complex Queries: Ability to handle complex queries and join operations between tables.
In summary:
a database is a collection of organized data
a DBMS is a tool for managing databases
a RDBMS is a type of DBMS that uses a relational model, typically supporting SQL for database access.
What is OLTP?
OLTP stands for Online Transaction Processing, is a class of software applications capable of supporting transaction-oriented programs. An essential attribute of an OLTP system is its ability to maintain concurrency. To avoid single points of failure, OLTP systems are often decentralized. These systems are usually designed for a large number of users who conduct short transactions. Database queries are usually simple, require sub-second response times, and return relatively few records. Here is an insight into the working of an OLTP system.
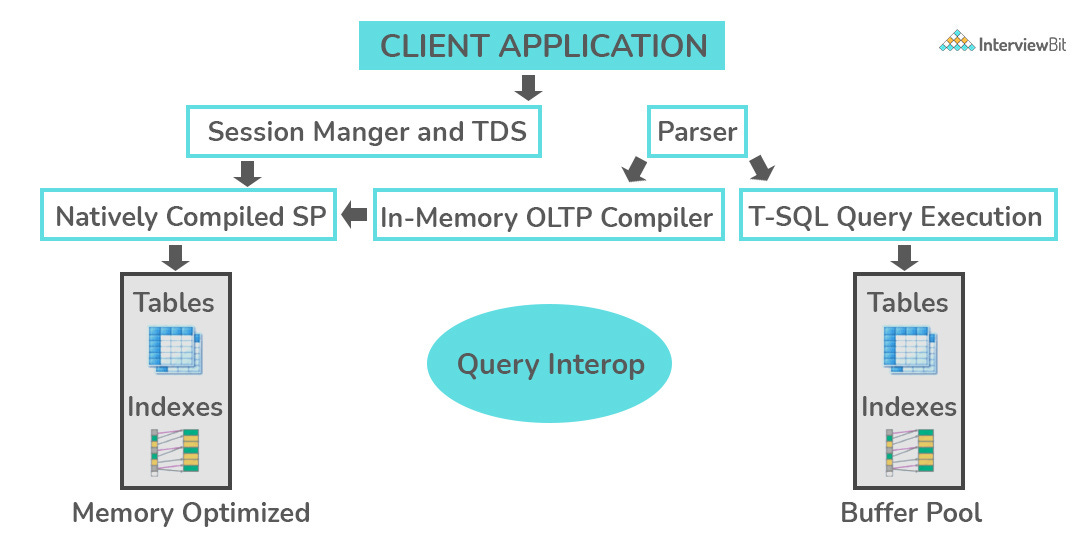
What are the differences between OLTP and OLAP?
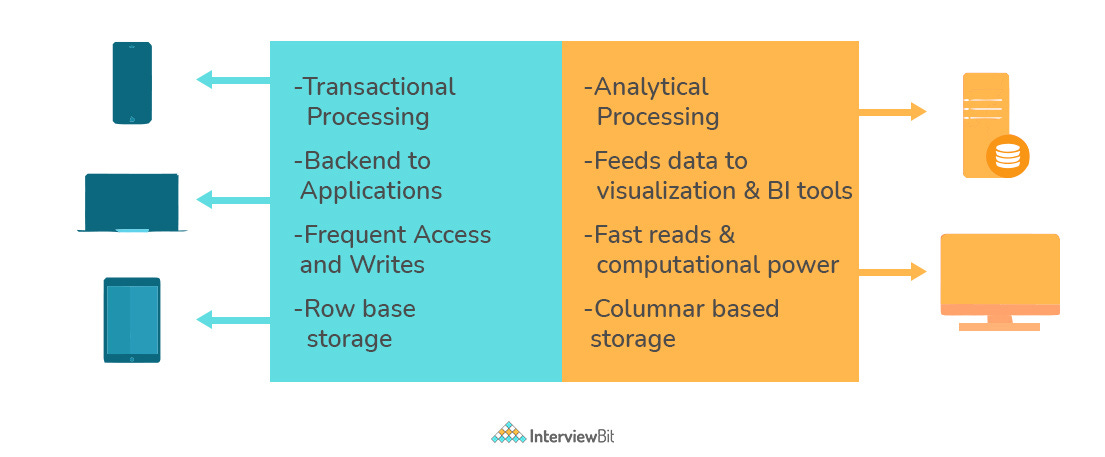
OLTP stands for Online Transaction Processing, is a class of software applications capable of supporting transaction-oriented programs. An important attribute of an OLTP system is its ability to maintain concurrency. OLTP systems often follow a decentralized architecture to avoid single points of failure. These systems are generally designed for a large audience of end-users who conduct short transactions. Queries involved in such databases are generally simple, need fast response times, and return relatively few records. A number of transactions per second acts as an effective measure for such systems.
OLAP stands for Online Analytical Processing, a class of software programs that are characterized by the relatively low frequency of online transactions. Queries are often too complex and involve a bunch of aggregations. For OLAP systems, the effectiveness measure relies highly on response time. Such systems are widely used for data mining or maintaining aggregated, historical data, usually in multi-dimensional schemas.
What are ACID properties?
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. They are defined as follows:
Atomicity. Atomicity requires that each transaction be “all or nothing”: if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors, and crashes.
Consistency. The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
Isolation. The isolation property ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e., one after the other. Providing isolation is the main goal of concurrency control. Depending on concurrency control method (i.e. if it uses strict - as opposed to relaxed - serializability), the effects of an incomplete transaction might not even be visible to another transaction.
Durability. Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the results need to be stored permanently (even if the database crashes immediately thereafter). To defend against power loss, transactions (or their effects) must be recorded in a non-volatile memory.
SQL Basics
What types of SQL commands (or SQL subsets) do you know?
In SQL, commands are categorized into five main types for managing and interacting with databases:
DML (Data Manipulation Language)
Used for data manipulation.
SELECT, INSERT, UPDATE, and DELETE
DDL (Data Definition Language)
Focuses on defining and altering the structure of the database objects.
CREATE, ALTER, DROP, and TRUNCATE
DCL (Data Control Language)
Manages access to the data.
GRANT and REVOKE
TCL (Transaction Control Language)
Manages database transactions to maintain data integrity.
COMMIT, ROLLBACK, SAVEPOINT, and SET TRANSACTION.
DQL (Data Query Language)
Primarily uses SELECT for querying and retrieving data from the database
focuses on extracting information without altering the data or its structure.
What SQL constraints do you know?
SQL constraints are rules applied to table columns to enforce data integrity and ensure the accuracy and reliability of the data within a database.
PRIMARY KEY: Uniquely identifies each row in a table. A table can have only one primary key, which can consist of single or multiple columns.
FOREIGN KEY: Establishes a relationship between two tables. It restricts the values to those already existing in the table it references, ensuring referential integrity.
UNIQUE: Ensures that all values in a column are unique, preventing duplicate entries in the specified column(s).
NOT NULL: Guarantees that a column cannot have a NULL value, ensuring that a value must be entered in that column for each row.
CHECK: Allows specifying a condition on the values that can be inserted into a column. If the condition is not met, the row cannot be inserted or updated.
DEFAULT: Assigns a default value to a column when no value is specified during the insertion of a row.
INDEX: While not a constraint in the strict sense, it is often discussed in the context of constraints as it affects how data is stored and accessed by improving the speed of data retrieval operations on a database table.
What is the difference between SQL and NoSQL database?
SQL and NoSQL databases differ significantly in structure, scalability, and use cases. Here’s a concise comparison:
SQL Databases
Structure: Relational, table-based with a predefined schema.
Query Language: Uses SQL for data manipulation and queries.
ACID Compliance: Strong consistency with ACID transactions for reliable data integrity.
Scalability: Primarily vertically scalable (scaling up server capacity).
Use Cases: Suitable for applications requiring complex transactions and strict data integrity, such as financial systems and inventory management.
Examples: MySQL, PostgreSQL, Oracle, Microsoft SQL Server
NoSQL Databases
Structure: Non-relational, supporting various data models (document, key-value, graph, wide-column) without a fixed schema.
Query Language: Custom query languages; no standard like SQL.
ACID Compliance: Originally focused on eventual consistency, though modern NoSQL databases often support ACID transactions in distributed systems.
Scalability: Designed for horizontal scaling (distribution across multiple servers).
Use Cases: Ideal for applications needing to handle large volumes of data with flexible data models, such as big data applications and content management systems.
Examples: MongoDB, Cassandra, Redis, Neo4j
Key Differences
Data Structure and Schema: SQL is structured and schema-dependent, NoSQL is flexible with schema-on-read.
Scalability: SQL scales vertically, NoSQL scales horizontally.
Transactions: SQL emphasizes ACID properties for transaction integrity, while NoSQL offers flexibility in consistency and scalability.
The choice between SQL and NoSQL depends on the application's specific data requirements, scalability needs, and the complexity of transactions.
What is the execution order of statements in a SELECT query?
SELECT
FROM
JOIN ON
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
LIMITHow to update a table?
Using the UPDATE statement. The syntax is:
UPDATE table_name
SET col_1 = value_1, col_2 = value_2
WHERE condition;What is the difference between renaming a column and giving an alias to it?
Renaming a column means permanently changing its actual name in the original table. Giving an alias to a column means giving it a temporary name while executing an SQL query, to make the code more readable and compact.
What is the difference between the DELETE and TRUNCATE statements?
DELETE is a reversible DML (Data Manipulation Language) command used to delete one or more rows from a table based on the conditions specified in the WHERE clause.
TRUNCATE is an irreversible DDL (Data Definition Language) command used to delete all rows from a table.
DELETE works slower than TRUNCATE. Also, we can't use the TRUNCATE statement for a table containing a foreign key.
What is the difference between the DROP and TRUNCATE statements?
DROP deletes a table from the database completely, including the table structure and all the associated constraints, relationships with other tables, and access privileges.
TRUNCATE deletes all rows from a table without affecting the table structure and constraints.
DROP works slower than TRUNCATE. Both are irreversible DDL (Data Definition Language) commands.
How to delete duplicate values in a table?
Deleting duplicate rows from a table in an SQL database can be a common task, especially when dealing with data that lacks proper constraints. The methods to achieve this can vary depending on the specific SQL database you are using (like MySQL, PostgreSQL, Oracle, SQL Server, etc.), but I'll provide a couple of general approaches that are widely applicable.
Method 1: Using a Temporary Table
This method involves creating a temporary table to store the distinct rows, deleting the original rows, and then inserting the distinct rows back into the original table.
-- Create a temporary table and insert distinct rows CREATE TEMPORARY TABLE temp_table AS SELECT DISTINCT * FROM your_table; -- Delete all rows from the original table DELETE FROM your_table; -- Insert distinct rows back into the original table INSERT INTO your_table SELECT * FROM temp_table; -- Drop the temporary table DROP TABLE temp_table;
Method 2: Using a Common Table Expression (CTE) with ROW_NUMBER
This method is useful in databases that support CTEs and window functions (SQL Server, PostgreSQL, Oracle). It assigns a row number to each row within a partition of a dataset and deletes rows with a row number higher than 1.
WITH cte AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY column1, column2, ... ORDER BY (SELECT NULL)) AS rn FROM your_table ) DELETE FROM cte WHERE rn > 1;In this query, replace column1, column2, ... with the columns that determine duplicates.
The ORDER BY (SELECT NULL) part is arbitrary since it doesn't matter how duplicates are ordered for deletion.
Method 3: Using GROUP BY and Aggregates
This method is a bit more complex and involves grouping and using aggregate functions. It's more suitable for databases like MySQL or SQLite that might not support the above methods.
DELETE t1 FROM your_table t1 JOIN ( SELECT MIN(id) as id, column1, column2, ... FROM your_table GROUP BY column1, column2, ... HAVING COUNT(*) > 1 ) t2 ON t1.id > t2.id WHERE t1.column1 = t2.column1 AND t1.column2 = t2.column2 ...;In this query, id is assumed to be a unique identifier for each row (like a primary key), and column1, column2, ... are the columns used to determine duplicates.
Important Notes
Always back up your table or database before performing bulk delete operations.
Test your query in a non-production environment first to ensure it works as expected.
The exact query syntax might need adjustments based on your specific SQL database system and schema.
If your table is large, these operations can be resource-intensive and time-consuming. Consider performance implications and possibly break down the operation into smaller batches if necessary.
Keys
What is a primary key?
A primary key is a unique identifier for each record in a database table, ensuring UNIQUE and NOT NULL values.
It can be a single column or a combination of multiple columns (composite primary key) when a single column isn't enough to ensure uniqueness.
Each table has exactly one primary key, crucial for maintaining data integrity and enabling efficient data retrieval.
What is a composite primary key?
A composite primary key uses multiple columns together to uniquely identify each row in a table, ensuring row uniqueness when a single column isn't enough.
What is a unique key?
A unique key is a constraint applied to a column (or set of columns) in a table to ensure that all values in the column(s) are distinct, allowing for one NULL value if NULLs are permitted.
Unlike a primary key, a table can have multiple unique keys. Each unique key guarantees that no two rows have the same value in the specified column(s), enhancing data integrity by preventing duplicate entries.
What is the difference between a primary key and a unique key?
A primary key uniquely identifies each row in a table and cannot be NULL, with each table having only one primary key.
A unique key prevents duplicate values in a column but allows for one NULL value and a table can have multiple unique keys.
What is a foreign key?
A foreign key is a column (or columns) in one table that references the primary key of another table, ensuring data consistency and establishing a relationship between tables. It enforces referential integrity by requiring that values in the foreign key column match values in the referenced table's primary key.
Indexes
What is an index?
An index in a database is a secondary data structure that allows for quick search and retrieval of data within a table. It works similarly to an index in a book, providing a shortcut to access the data without scanning the entire table. By maintaining a sorted list of key values and pointers to their corresponding records in the table, indexes make search operations, such as lookups and joins, much faster.
CREATE INDEX index_name ON table_name (column_1, ...);
DROP INDEX index_name; What types of indexes do you know?
In relational databases, indexes are used to speed up the retrieval of data from tables. There are several types of indexes, each designed for specific use cases and database engines. The availability and specifics of these index types can vary depending on the database management system (DBMS) being used, such as MySQL, PostgreSQL, Oracle, SQL Server, etc. Here are some of the common types of indexes:
Clustered Indexes
In a clustered index configuration, the arrangement of rows in the index is identical to the sequence of rows in the database itself.
Due to the physical sorting of data rows according to the index, only a single clustered index is feasible for each table.
This indexing method enhances the efficiency of specific query operations, notably those involving the retrieval of data ranges.
In systems like SQL Server, where tables are inherently structured with clustered indexes, Oracle, through Index-Organized Tables, and MySQL's InnoDB engine, which permits a singular clustered index usually designated as the primary key.
Use cases: Primarily advantageous for columns that are regularly involved in sort and range-based queries.
Advantages: Enables swift data retrieval as information is organized in the order of the index.
Limitations: Restricted to one per table, potentially hindering the speed of data insertions and modifications.
Non-Clustered Indexes
The architecture of a non-clustered index is distinct from the physical layout of the data rows.
Tables are capable of supporting numerous non-clustered indexes.
For data retrieval, they are generally not as swift as clustered indexes, yet they offer improved performance for insertions and updates.
These indexes are compatible with SQL Server, MySQL, Oracle, and PostgreSQL databases.
Oracle and PostgreSQL prominently utilize non-clustered indexes, albeit with some constraints. In MySQL and SQL Server, their application is not as prevalent in the same manner.
Use cases: Beneficial for columns that are frequently utilized in search criteria but not suited for range queries.
Advantages: Allows for the creation of several non-clustered indexes on a single table.
Limitations: Necessitates extra storage space; retrieval operations are slower compared to clustered indexes.
B-Tree Indexes
B-tree (Balanced Tree) indexes, the most prevalent form of indexing, utilize a hierarchical tree structure to store data, facilitating effective search, insertion, deletion, and range query operations.
These indexes excel with data of high cardinality, meaning columns that possess unique or almost unique values.
Virtually all relational database management systems (DBMS) support B-tree indexes, including MySQL, PostgreSQL, Oracle, SQL Server, SQLite, among others.
To create a B-tree index,
CREATE INDEX idx_name ON table_name (column_name);Use cases: B-tree indexes are exceptionally suited for a broad spectrum of general-purpose queries, notably those that require range searches, equality searches, and sorting.
Advantages: Offers great flexibility and efficiency across various query types.
Limitations: Their efficiency may decline in scenarios involving low-cardinality fields, where there are numerous duplicate values in a column.
Hash Indexes
Hash indexes are employed within hash-based databases and are optimized for equality comparison operations.
By utilizing a hash function to determine data locations, hash indexes enable exceedingly rapid direct lookup queries.
However, they are not conducive to range queries due to their inability to maintain data in a sorted sequence.
These indexes are notably supported by several DBMS, including MySQL (specifically for its MEMORY engine), PostgreSQL, Oracle, and SQL Server (where it functions as a nonclustered hash index).
For PostgreSQL, the syntax to create a hash index is:
CREATE INDEX idx_name ON table_name USING HASH (column_name);While MySQL and certain other DBMS may not offer explicit support for hash indexes in the same fashion.
Use cases: Primarily advantageous for tables predominantly queried through equality comparisons.
Advantages: Offers unparalleled speed for direct lookup operations.
Limitations: Ill-suited for range queries and can suffer performance issues in instances of high collision rates.
Composite (or Compound) Indexes
Composite (or Compound) indexes are constructed across multiple columns within a database table, enhancing the efficiency of queries that involve many or all of the indexed columns.
The sequence of columns specified in the index's definition plays a critical role in optimizing queries, making it a key consideration during index creation.
These indexes receive broad support from various relational databases, including MySQL, PostgreSQL, Oracle, SQL Server, among others, demonstrating their widespread applicability.
Use cases: Particularly beneficial for scenarios where queries necessitate filtering or sorting based on multiple columns.
Advantages: When applied appropriately, composite indexes can significantly enhance the performance of queries, making data retrieval operations more efficient.
Limitations: These indexes tend to be larger in size, and the criticality of column order within the index can restrict their effectiveness for certain query types.
Unique Indexes
Unique indexes are designed to guarantee the uniqueness of index values, preventing any two rows from sharing the same value within the indexed column(s).
These indexes are a standard method for ensuring the uniqueness of a single column or a combination of columns, making them a critical tool for data integrity across various applications.
Their utility is recognized and supported by all major database management systems (DBMS), including MySQL, PostgreSQL, Oracle, and SQL Server, highlighting their essential role in database management.
Use cases: Ideal for any situation requiring the enforcement of unique values within a column, such as email addresses, usernames, or any other identifier needing to be distinct.
Advantages: By prohibiting duplicate entries, unique indexes play a pivotal role in maintaining the integrity of the data stored within a database.
Limitations: The process of verifying the uniqueness of each inserted or updated value introduces additional overhead, which can lead to slower data insertion operations.
Full-Text Indexes
Full-Text indexes are specifically crafted to facilitate full-text search operations, indexing the individual words within text-based columns to enable efficient textual data searches.
These indexes are particularly prevalent in applications or systems that require the searchability of extensive text fields, such as content management systems, search engines, and databases storing large documents.
Supported by a variety of database management systems, including MySQL, PostgreSQL (which can utilize extensions like Tsearch2 for enhanced functionality), Oracle, and SQL Server—where the Full-Text Search feature is a notable implementation.
Use cases: Perfectly suited for handling columns populated with significant text volumes, such as articles, product descriptions, and any extensive textual content.
Advantages: Full-Text indexes significantly improve the efficiency of searching through text data, offering powerful capabilities for full-text search queries that go beyond simple keyword matching.
Limitations: The creation of Full-Text indexes results in a larger index footprint, which can impact storage requirements. Additionally, updates to the indexed text data might occur at a slower pace due to the complexity of maintaining the index.
Partial (or Filtered) Indexes
Partial (or Filtered) indexes target a specific subset of rows within a table for indexing, making them an efficient choice when only a fraction of the table's data is queried regularly.
These indexes are particularly useful for optimizing performance, as they are smaller and quicker to search compared to indexes that cover all rows of a table.
Supported by several relational database management systems, including PostgreSQL, SQL Server, and Oracle, filtered indexes are a versatile tool for database optimization.
Use cases: Especially advantageous for scenarios where frequent queries are performed on a distinct subset of the table's rows.
Advantages: Due to their reduced size, partial indexes can offer improved performance by decreasing the search space and resource usage, which can be particularly beneficial for large databases.
Limitations: Their utility is confined to specific query types, which can limit their applicability. Additionally, the complexity of maintaining these indexes may increase, especially as the criteria defining the indexed subset change over time.
Bitmap Indexes
Bitmap indexes are primarily utilized in scenarios such as data warehousing, where the targeted column exhibits low cardinality, meaning it contains a relatively small number of distinct values. By employing bitmap representations for indexing, these indexes achieve high efficiency for specific query types, making them particularly suitable for analytical queries on columns with limited distinct values.
This indexing technique finds its application in various database management systems (DBMS) including specialized functionalities within MySQL for spatial data types in MyISAM and InnoDB engines, PostgreSQL enhanced with the PostGIS extension for spatial data, Oracle Spatial for complex geographic data structures, and SQL Server, which offers extensive support for spatial and analytical workloads.
Use cases: Bitmap indexes are most beneficial for columns characterized by a limited set of distinct values, such as gender, status flags, or any other categorical data that does not vary widely across the dataset.
Advantages: For the right types of queries and data characteristics, bitmap indexes provide exceptional efficiency, significantly enhancing query performance in data warehousing environments by enabling fast filtering and aggregation of data.
Limitations: Their utility diminishes in contexts involving high-cardinality data, where the diversity of values negates the efficiency gains of bitmap indexing. Additionally, environments with high transaction volumes or frequent updates may encounter performance degradation, as the process of updating bitmap indexes can be more resource-intensive compared to other indexing strategies.
Spatial Indexes
Spatial indexes are specifically engineered for managing spatial data, such as coordinates, polygons, and other geographic entities. These indexes are instrumental in optimizing queries that perform spatial operations, for instance, identifying all locations within a specified distance, or determining spatial relationships between different geographic features.
Supported across a range of database management systems, spatial indexes are available in SQL Server, MySQL, PostgreSQL (often with the PostGIS extension for enhanced spatial capabilities), and Oracle, each offering specialized functionalities to handle complex spatial data efficiently.
Use cases: Spatial indexes are crucial for any application that deals with geographical data, including mapping services, location-based services, and geographic information systems (GIS) where queries frequently involve spatial considerations.
Advantages: By enabling efficient querying and manipulation of spatial data, spatial indexes significantly improve performance for operations such as proximity searches, spatial joins, and area calculations, making them indispensable for spatial analysis and geographic data management.
Limitations: The specificity to spatial data means that these indexes are more complex to implement and maintain compared to standard indexing methods. This complexity arises from the need to accommodate the multidimensional nature of spatial data and the specialized operations that spatial queries entail.
Covering Indexes
Covering indexes are a type of index that encompasses all the columns needed for a particular query. By incorporating every column required by the query within the index itself, it obviates the necessity for additional data lookups, leading to significant improvements in query performance.
These indexes find their utility in scenarios where a query is designed to select multiple columns from the same table. By ensuring that all the data required for the query is directly available within the index, covering indexes can substantially reduce the query execution time.
Use cases: Particularly useful for queries that involve retrieving multiple columns from a table, covering indexes optimize the retrieval process by providing all the needed data within the index itself.
Advantages: The primary advantage of covering indexes is the marked enhancement in query performance they offer. Since the index directly contains all the data required for the query, it eliminates the need for the query processor to access the table data separately, thereby speeding up query execution.
Limitations: One of the drawbacks of covering indexes is their larger size compared to indexes that include only a subset of columns. This increased size can lead to higher storage requirements. Additionally, their effectiveness may be diminished in tables with a high number of columns, as including too many columns in an index can make it unwieldy and less efficient.
Expression/Index-Organized Tables
In certain databases, indexes can be created on both columns and expressions or functions, enhancing query efficiency. Additionally, Index-Organized Tables (IOTs) integrate the table data within the index structure for faster key-based access.
Expression-based indexes, available in PostgreSQL and Oracle, optimize queries involving calculated data. Index-Organized Tables, specific to Oracle, excel in OLTP systems with primary key access patterns.
Use cases:
Expression indexes suit queries with calculated data.
IOTs are ideal for efficient, key-based data retrieval in transactional systems.
Advantages:
Expression indexes improve query speed for calculations.
IOTs enable rapid primary key lookups and efficient space use.
Limitations:
Expression indexes add complexity to query optimization.
IOTs demand careful planning due to their structured nature and are less flexible in accommodating various access patterns.
It's important to note that the implementation details and performance implications of these indexes can vary significantly between different DBMS.
Additionally, some types of indexes might be known by different names or have slightly different characteristics in different systems.
Always refer to the specific documentation of the DBMS you are using for the most accurate and detailed information.
What is the difference between clustered and non-clustered indexes?
While a clustered index defines the physical order of records of a table and performs data searching based on the key values, a non-clustered index keeps the order of records that don't match the physical order of the actual data on the disk. A table can have only one clustered index but many non-clustered ones.
What is the difference between unique and non-unique index?
Unique indexes are indexes that help maintain data integrity by ensuring that no two rows of data in a table have identical key values. Once a unique index has been defined for a table, uniqueness is enforced whenever keys are added or changed within the index.
CREATE UNIQUE INDEX myIndex ON students (enroll_no);Non-unique indexes, on the other hand, are not used to enforce constraints on the tables with which they are associated. Instead, non-unique indexes are used solely to improve query performance by maintaining a sorted order of data values that are used frequently.
What are all the different attributes of indexes?
Indexes in databases optimize data retrieval but have various attributes impacting performance and storage:
Access Types
Value-based search: Direct access using a specific value.
Range access: Retrieval of records within a specified range.
Others: Full-text search for textual data, hash-based for direct location access.
Access Time
Time required to locate and retrieve data, influenced by the index's structure (e.g., B-trees, hash tables).
Insertion Time
Time to insert a new record and update the index, depending on the complexity of the index structure.
Deletion Time
Time needed to remove a record and adjust the index, similar to insertion time.
Space Overhead
Additional storage space required by the index, varies by index type and complexity.
Other Considerations
Uniqueness: Determines if the index enforces unique values.
Maintenance Cost: Effort to keep the index updated with database changes.
Concurrency Control: Handling of simultaneous operations by multiple users.
Efficient index design balances these attributes to optimize database performance and storage requirements.
What is a heap table?
A heap table is a database table without a clustered index, where data is stored in an unordered fashion. This structure allows for efficient data insertion but can lead to slower search and retrieval operations compared to tables with indexes.
SQL Functions and Procedures
What types of SQL functions do you know?
Aggregate functions: These operate on multiple records, typically grouped, within specified columns of a table, yielding a singular value, often per group.
Scalar functions: These act on individual values, producing a solitary result for each.
Window functions: These functions perform calculations across a set of rows related to the current row within a query result. They allow for flexible analysis and manipulation of data within specific partitions.
Additionally, SQL functions can be classified as either built-in (provided by the system) or user-defined (crafted by users to suit particular requirements). needs).
What aggregate functions do you know?
AVG()– returns the average valueSUM()– returns the sum of valuesMIN()– returns the minimum valueMAX()– returns the maximum valueCOUNT()– returns the number of rows, including those with null valuesFIRST()– returns the first value from a columnLAST()– returns the last value from a column
What scalar functions do you know?
LEN()(in other SQL flavors –LENGTH()) – returns the length of a string, including the blank spacesUCASE()(in other SQL flavors –UPPER()) – returns a string converted to the upper caseLCASE()(in other SQL flavors –LOWER()) – returns a string converted to the lower caseINITCAP()– returns a string converted to the title case (i.e., each word of the string starts from a capital letter)MID()(in other SQL flavors –SUBSTR()) – extracts a substring from a stringROUND()– returns the numerical value rounded to a specified number of decimalsNOW()– returns the current date and time
What is a User-defined function? What are its various types?
A User-Defined Function (UDF) in SQL is a function created by the user to perform actions that are not available through built-in functions. UDFs allow you to encapsulate complex logic and calculations, making them reusable across multiple SQL queries or stored procedures. There are generally two main types of UDFs in most SQL database systems:
Scalar Functions
Scalar functions return a single value each time they are invoked. This value can be of various data types like integer, float, varchar, date, etc. Scalar UDFs are useful when you need to perform operations that result in a single value based on input values.
CREATE FUNCTION function_name (
-- Input parameters
@parameter1 datatype1,
@parameter2 datatype2
)
RETURNS return_datatype
AS
BEGIN
-- Body of the function
DECLARE @result return_datatype;
-- Function logic
-- You can use SELECT, SET, or other SQL statements to manipulate data
-- Example:
-- SET @result = some_operation(@parameter1, @parameter2);
-- Return the result
RETURN @result;
END;
-- To use the function:
SELECT db_name.function_name(parameter1, parameter2);Table-Valued Functions (TVFs)
Table-Valued Functions return a table data type. There are two types of TVFs:
Inline Table-Valued Functions
These functions use a single SELECT statement and cannot have other logic within them.
CREATE FUNCTION function_name (
-- Input parameters
@parameter1 datatype1,
@parameter2 datatype2
)
RETURNS TABLE
AS
RETURN
(
-- Query to generate the table
SELECT column1, column2, ...
FROM your_table
WHERE condition
);
-- To use the function:
SELECT * FROM db_name.function_name(parameter1, parameter2)Multi-Statement Table-Valued Functions
These functions can have multiple statements including complex logic, and can use temporary tables or table variables.
CREATE FUNCTION function_name (
-- Input parameters
@parameter1 datatype1,
@parameter2 datatype2
)
RETURNS @return_table TABLE (
-- Table columns
column1 datatype1,
column2 datatype2,
...
)
AS
BEGIN
-- Function logic to populate the table variable
INSERT INTO @return_table (column1, column2, ...)
SELECT column1, column2, ...
FROM your_table
WHERE condition;
-- Additional statements if needed
-- Return the populated table variable
RETURN;
END;
-- To use the function:
SELECT * FROM db_name.function_name(parameter1, parameter2)Notes
The syntax for creating UDFs can vary slightly between different SQL databases like MySQL, PostgreSQL, Oracle, and SQL Server.
UDFs should be used judiciously as they can sometimes lead to performance issues, especially if they contain complex logic or are used within large queries.
What is a Stored Procedure?
A stored procedure is a subroutine available to applications that access a relational database management system (RDBMS). Such procedures are stored in the database data dictionary.
The sole disadvantage of stored procedure is that it can be executed nowhere except in the database and occupies more memory in the database server.
It also provides a sense of security and functionality as users who can't access the data directly can be granted access via stored procedures.
DELIMITER $$
CREATE PROCEDURE ProcedureName
-- Add parameters here if needed
-- @Parameter1 DataType,
-- @Parameter2 DataType,
AS
BEGIN
-- Body of the stored procedure
-- SQL statements here
END $$
DELIMITER ;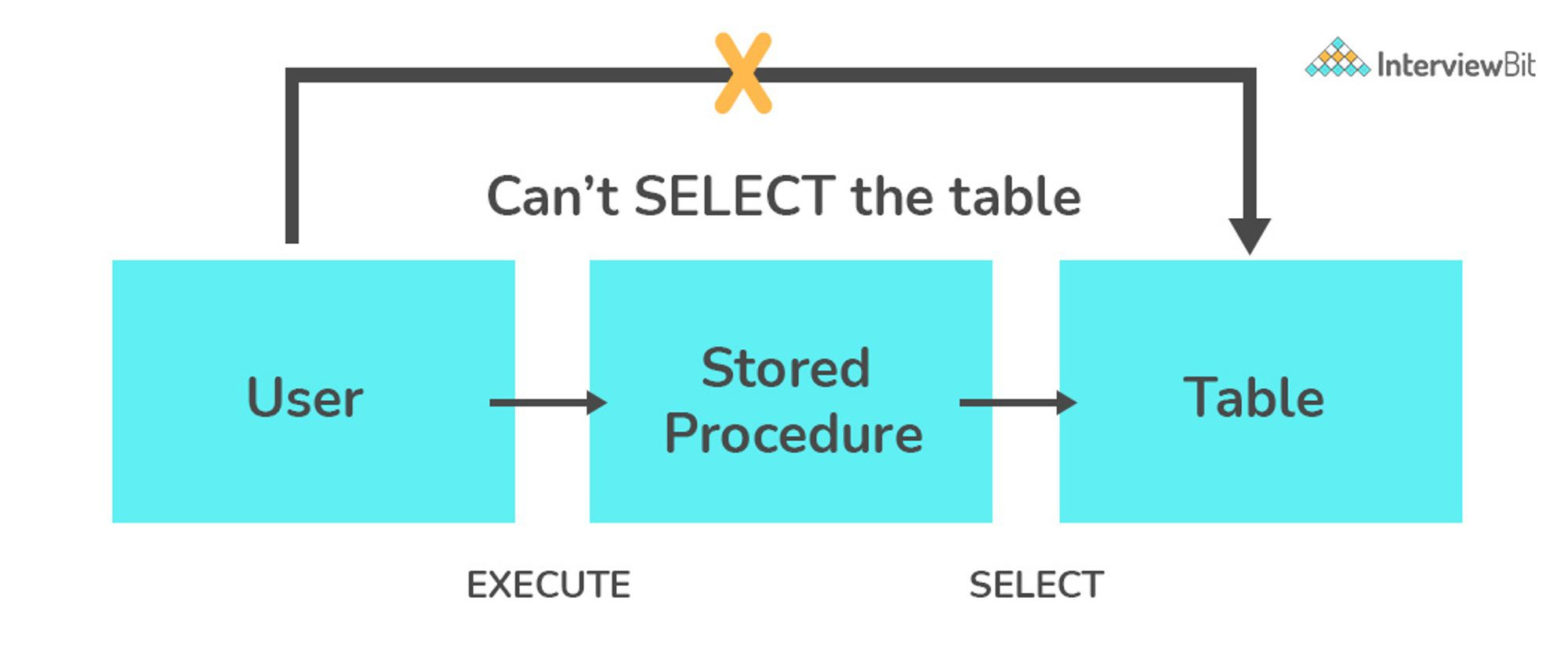
Stored procedures in relational database management systems (RDBMS) act as subroutines, stored within the database's data dictionary, executing SQL statements and control-flow logic. However, a key disadvantage is their limited execution context, binding them to the database environment.
Advantages include enhanced security through controlled data access, encapsulation of complex operations for simplified execution, and granular access control for users.
Stored procedures' speed is attributed to precompilation, reduced network traffic, batch processing, optimized execution plans, encapsulated business logic, avoidance of SQL injection and caching.
However, their performance advantages vary based on factors such as operation complexity, database design, code efficiency, and the specific DBMS used.
What is the difference between Stored Procedures and Functions?
Stored Procedures and Functions are two fundamental components of SQL databases designed for modular and reusable SQL code, but they serve different purposes and have distinct features:
Stored Procedures
Purpose: Perform a series of operations or queries on a database. They are versatile and can encapsulate complex business logic or data manipulation tasks.
Return Values: Can return zero, one, or multiple result sets, but not limited to data return.
Parameters: Accept input and output parameters, allowing them to return multiple values via OUT parameters.
Data Modification: Capable of performing data modification operations like INSERT, UPDATE, DELETE, etc.
Transactions: Can contain transactional logic, with the ability to roll back transactions if errors occur.
Usage: Suited for complex business logic, batch processing, and comprehensive data manipulation.
Example:
-- Template for Creating a Stored Procedure
CREATE PROCEDURE ProcedureName
@Parameter1 DataType1,
@Parameter2 DataType2
AS
BEGIN
-- SQL operation to be performed, e.g., UPDATE, INSERT
UPDATE TableName SET ColumnName1 = @Parameter2 WHERE ColumnName2 = @Parameter1;
END
-- To call the stored procedure
EXEC ProcedureName @Parameter1 = Value1, @Parameter2 = Value2;Functions
Purpose: Compute values based on input parameters. They are primarily used for calculations, data transformation, or returning specific information.
Return Values: Must return a single value or a table (table-valued functions).
Parameters: Only accept input parameters.
Data Modification: Generally cannot modify the database state. Designed for read-only operations.
Transactions: Not used for transactional logic.
Usage: Commonly utilized in SELECT statements, WHERE/HAVING clauses for data computation or transformation.
Example:
-- Template for Creating a Scalar-Valued Function
CREATE FUNCTION FunctionName
(@Parameter1 DataType1, @Parameter2 DataType2)
RETURNS ReturnType
AS
BEGIN
-- Computation or operation to perform and return a result
RETURN ExpressionUsingParameters;
END
-- Example call to the function
SELECT dbo.FunctionName(@Parameter1 = Value1, @Parameter2 = Value2) AS AliasNameKey Differences
Return Type and Usage: Stored Procedures can be more flexible in terms of data return, not necessarily returning a value, and can be used for a wide range of operations. Functions must return a value and are primarily used within SQL statements for data manipulation or computation.
Modification Capabilities: Functions are typically read-only, whereas Stored Procedures can perform operations that modify the database.
Parameter Types: Stored Procedures can have output parameters to return data, unlike functions.
The choice between Stored Procedures and Functions should be based on the specific requirements of the task, considering the need for data modification, transaction management, and integration within SQL queries.
Functions are ideal for direct integration with SQL statements for data computation.
Stored Procedures are suited for more complex tasks that may involve multiple steps or data manipulation.
Triggers and Views
What is a trigger?
A trigger is an automatic system-executed statement triggered by modifications within the database.
It is defined by specifying both the timing of its execution and the specific actions to be carried out.
Triggers serve to enforce integrity and referential constraints beyond what can be achieved through SQL's standard constraint mechanisms.
CREATE TRIGGER trigger_name
BEFORE | AFTER | INSTEAD OF -- Choose when the trigger should fire
INSERT | UPDATE | DELETE -- Choose the operation that activates the trigger
ON table_name -- The table on which the trigger operates
FOR EACH ROW -- Specifies that the trigger should fire for each row affected
BEGIN
-- Trigger logic here
-- Example: SET NEW.column_name = 'value' (for BEFORE INSERT/UPDATE triggers)
-- Example: INSERT INTO another_table VALUES (OLD.column_name) (for AFTER DELETE triggers)
END;What is a view, and why use it?
A virtual table containing a subset of data retrieved from one or more database tables (or other views). Views take very little space, simplify complex queries, limit access to the data for security reasons, enable data independence, and summarize data from multiple tables.
Can we create a view based on another view?
Yes. This is also known as nested views. However, we should avoid nesting multiple views since the code becomes difficult to read and debug.
Can we still use a view if the original table is deleted?
No. Any views based on that table will become invalid after deleting the base table. If we try to use such a view anyway, we'll receive an error message.
What is a materialized view?
A materialized view is a database object that contains the results of a query. Unlike a standard view, which dynamically calculates the results every time it is accessed, a materialized view stores the query result data physically, making data retrieval much faster at the cost of additional storage and the need for periodic refreshes to keep the data up-to-date.
Joins and Set Operators
What types of joins do you know?
In SQL, joins are used to combine rows from two or more tables based on a related column between them. Here are the main types of joins:
(INNER) JOIN: Returns rows when there is at least one match in both tables. If there is no match, the rows are not returned. Default SQL join.
LEFT JOIN (or LEFT OUTER JOIN): Returns all rows from the left table, and the matched rows from the right table. The result is NULL on the right side when there is no match.
RIGHT JOIN (or RIGHT OUTER JOIN): Returns all rows from the right table, and the matched rows from the left table. The result is NULL on the left side when there is no match.
FULL JOIN (or FULL OUTER JOIN): Returns rows when there is a match in one of the tables. This means it returns all rows from both tables, with matching rows from both sides where available. If there is no match, the result is NULL on the side without a match.
CROSS JOIN: Returns a Cartesian product of the two tables, i.e., it joins every row of the first table with every row of the second table.
SELF JOIN: A join of a table to itself as if the table were two separate tables; this is useful for comparing rows within the same table.
NATURAL JOIN: Automatically joins tables based on columns with the same names and data types in both tables. It performs an INNER JOIN, eliminating duplicate columns by only including one column for each pair of identically named columns.
What is a Self-Join?
A self JOIN is a case of regular join where a table is joined to itself based on some relation between its own column(s). Self-join uses the INNER JOIN or LEFT JOIN clause and a table alias is used to assign different names to the table within the query.
Write a SQL statement to perform SELF JOIN for 'Table_X' with alias 'Table_1' and 'Table_2', on columns 'Col_1' and 'Col_2' respectively
SELECT Table_1.Col_1, Table_2.Col_2
FROM Table_X AS Table_1
JOIN Table_X AS Table_2 ON Table_1.Col_1 = Table_2.Col_2;What is a Cross-Join?
Cross join can be defined as a cartesian product of the two tables included in the join. The table after join contains the same number of rows as in the cross-product of the number of rows in the two tables. If a WHERE clause is used in cross join then the query will work like an INNER JOIN.
Write a SQL statement to CROSS JOIN 'table_1' with 'table_2' and fetch 'col_1' from table_1 & 'col_2' from table_2 respectively. Do not use alias.
SELECT table_1.col_1, table_2.col_2
FROM table_1
CROSS JOIN table_2;What set operators do you know?
UNION – returns the records obtained by at least one of two queries (excluding duplicates)
UNION ALL – returns the records obtained by at least one of two queries (including duplicates)
INTERSECT – returns the records obtained by both queries
EXCEPT (called MINUS in MySQL and Oracle) – returns only the records obtained by the first query but not the second one
SQL Commands Comparison
What is the difference between the RANK() and DENSE_RANK() functions? Provide an example.
RANK() and DENSE_RANK() are SQL functions used to assign rankings to rows based on their values in a partition. The key difference lies in how they handle ties: RANK() leaves gaps in the ranking sequence after ties, while DENSE_RANK() does not, ensuring consecutive rankings throughout.
For example consider scores: {10, 20, 20, 30}:
Using RANK(), the scores are ranked as {1, 2, 2, 4}, skipping rank 3 due to the tie.
With DENSE_RANK(), the rankings are {1, 2, 2, 3}, with no gap after the tie.
What is the difference between char and varchar2?
In a database, the varchar2 data type allocates space based on the actual length of the stored content. For instance, if a column is defined as varchar2(1999) and you store a value that is 50 bytes long, it will occupy 52 bytes of space.
Conversely, the char data type reserves and utilizes the full specified length, padding any unused space with blanks. Thus, if a column is defined as char(1999) and stores a value of 50 bytes, it will still consume 2000 bytes of storage.
What is the difference between IN and EXISTS?
IN and EXISTS are SQL keywords with distinct behaviors:
IN:
Targets list result sets for direct value comparisons.
Ineffective with subqueries producing multi-column virtual tables.
Compares all list values, slowing down with large subquery result sets.
EXISTS:
Efficient with virtual tables and correlated subqueries.
Stops as soon as a match is found, enhancing performance.
Generally faster with larger subquery result sets due to its early-exit strategy.
What is Auto Increment?
Auto Increment is a database feature that automatically generates a unique numerical Primary Key for each new record, simplifying the process when a unique identifier is not available in the table. This functionality, supported by all major databases, eliminates the need for manual key assignment. For more details, see the SQL Auto Increment documentation.
Database Schema Design
What types of SQL relationships do you know?
One-to-one – "--o" – each record in one table corresponds to only one record in another table
One-to-many – "--|" – each record in one table corresponds to several records in another table
Many-to-many – "--< " – each record in both tables corresponds to several records in another table
What is normalization in SQL, and why use it?
Normalization is a process of database design that includes organizing and restructuring data in a way to reduces data redundancy, dependency, duplication, and inconsistency. This leads to enhanced data integrity, more tables within the database, more efficient data access and security control, and greater query flexibility.
What are the various forms of Normalization?
First Normal Form (1NF)
Ensures each column contains single, indivisible values and removes duplicate columns.
Example:
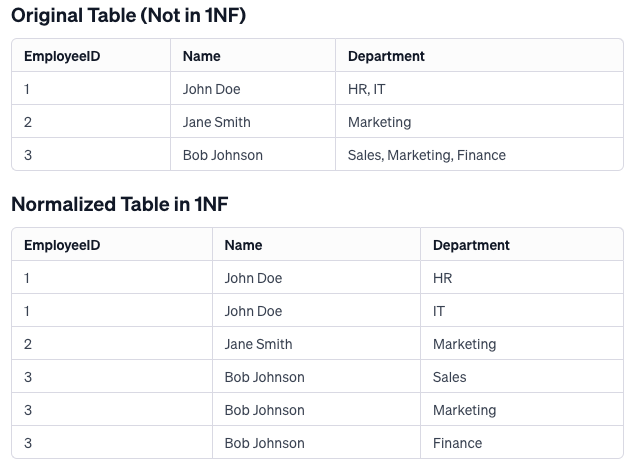
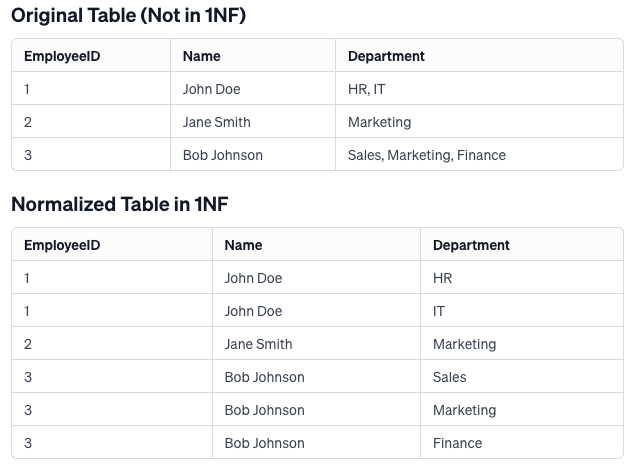
Explanation
In the original table, the
Departmentcolumn violates 1NF because it contains multiple values for some employees. To normalize the table to 1NF, theDepartmentdata is separated such that each employee-department combination occupies a distinct row, ensuring all values are atomic and each row represents a unique piece of information. This restructuring eliminates the multi-valued attribute issue, aligning the table with the requirements of 1NF.
Second Normal Form (2NF)
Builds on 1NF and ensures that all non-key attributes are fully dependent on the primary key, avoiding partial dependencies.
Example:
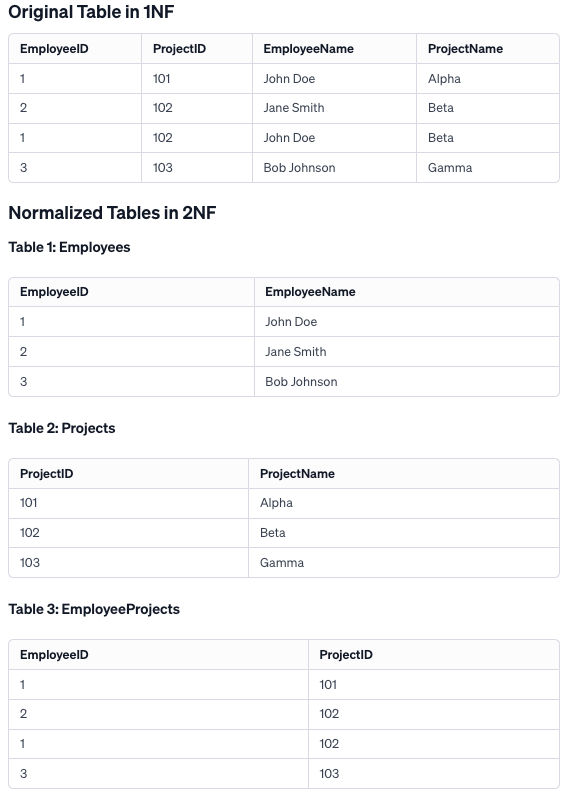
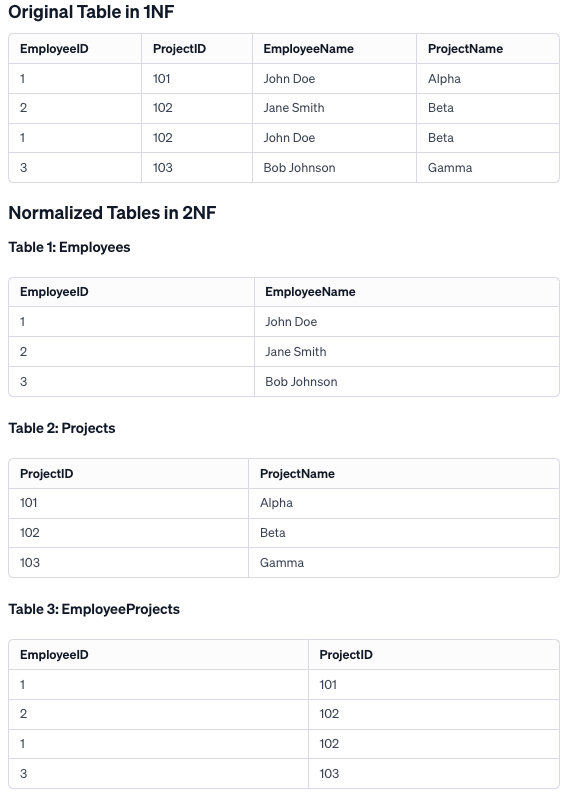
Explanation
To achieve 2NF, the original table was decomposed into three tables: Employees, Projects, and EmployeeProjects. This eliminates partial dependencies, with each non-key attribute being fully functionally dependent on the primary key of its table. The EmployeeProjects table serves to maintain the association between employees and projects, effectively addressing the many-to-many relationship and ensuring data integrity with reduced redundancy.
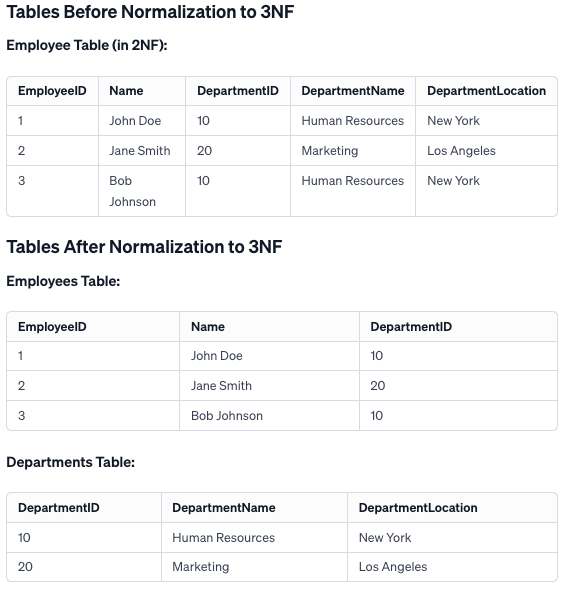
Third Normal Form (3NF)
Extends 2NF by eliminating dependencies where non-key attributes depend on other non-key attributes, promoting simplicity.
Example:
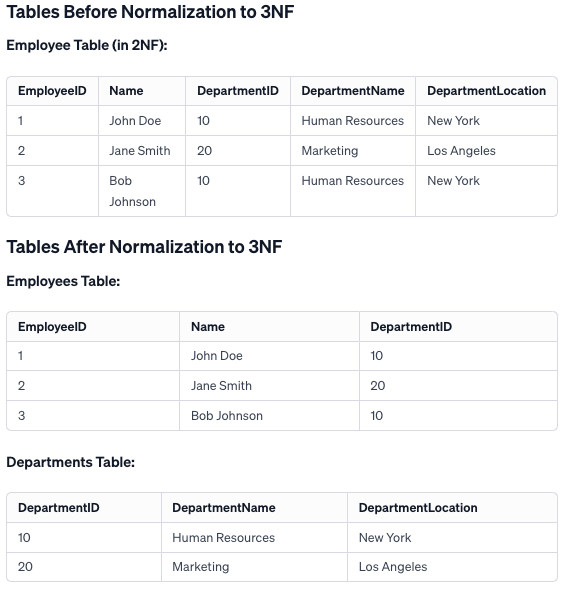
Explanation
In transitioning from 2NF to 3NF, the goal was to remove transitive dependencies. The original table contained both employee information and department details, leading to redundancy.
By creating two separate tables, one for employees and another for departments, we ensure that all attributes in each table are only dependent on the primary key. This restructuring avoids redundancy, simplifies updates, and enhances data integrity, aligning the design with the principles of 3NF.
Boyce-Codd Normal Form (BCNF)
Similar to 3NF but focuses on ensuring that every non-trivial dependency involves a candidate key.
Fourth Normal Form (4NF)
Addresses multi-valued dependencies, ensuring no sets of values can have multiple values for a single key.
Fifth Normal Form (5NF) or Project-Join Normal Form (PJNF)
Focuses on making sure a table can be reconstructed from smaller parts, especially in complex scenarios with multiple tables and joins.
These normal forms guide how to structure databases efficiently, reducing redundancy and maintaining data integrity. The choice of which normal form to apply depends on the specific needs of the database design.
What is denormalization in SQL, and why use it?
Denormalization is the process opposite of normalization: it introduces data redundancy and combines data from multiple tables. Denormalization optimizes the performance of the database infrastructure in situations when read operations are more important than write operations since it helps avoid complex joins and reduces the time of query running.
SQL Optimization
Give examples of sql optimization?
Indexing: Creating indexes on columns frequently used in WHERE clauses or as join keys to speed up data retrieval.
Query Refactoring: Rewriting queries to reduce complexity, such as avoiding subqueries, minimizing the use of wildcard operators, and using joins instead of multiple queries.
Partitioning: Dividing large tables into smaller, more manageable pieces to improve query performance.
What is an execution plan? When would you use it? How would you view the execution plan?
An execution plan is a guide, either graphical or textual, that outlines how the SQL server's query optimizer intends to execute a stored procedure or ad hoc query. It's invaluable for developers to assess and enhance the performance of queries or stored procedures by showing the methods of data retrieval used.
To access an execution plan, different SQL systems offer various tools. For instance, the `EXPLAIN` keyword can generate a textual execution plan in many systems. Graphical representations are also available in certain environments. Specifically, in Microsoft SQL Server, the Query Analyzer provides a "Show Execution Plan" option within the Query menu, which, when enabled, visually presents the execution plan in a new window after a query is executed.