

This post effectively encapsulates the core elements relevant to SQL and relational database management. It highlights the importance of understanding database fundamentals, schema design, and SQL syntax while also delving into optimization, scaling, and database systems like MySQL and PostgreSQL. By addressing scalability, security against SQL injection, and data manipulation strategies, it underscores the practical aspects crucial for mastering database administration and SQL programming. This guide serves as a comprehensive resource for individuals aiming to acquire foundational knowledge and develop practical skills in the field.
Sources:
Contents:
Annotations
Database concepts
Databases: Structured collections of data for efficient storage and management.
Relational Databases: A type of database using tables with rows and columns, connected by keys. Commonly used with SQL.
RDBMS (Relational Database Management System): Software for creating, managing, and querying relational databases. Examples include MySQL and PostgreSQL.
Relational database elements
Tables
Tables are containers that store data in a structured manner. They consist of rows and columns, with each column representing a specific attribute of the data, and each row containing a unique data record.
Columns
Columns define the type of data that can be stored in a table. They have names and data types (e.g., text, numbers, dates) that specify the kind of information they can hold. For instance, a "product_name" column stores text data, while a "price" column stores numerical values.
Rows
Rows, also known as records, represent individual data entries within a table. Each row contains values for each of the table's columns, forming a complete data record. For example, a row in an "employees" table may represent a specific employee's details.
Primary Key
A primary key is a column or a combination of columns that ensures each row in a table has a unique identifier. It enforces data integrity by preventing duplicate entries and serves as the primary means of identifying and retrieving specific records.
Foreign Key
A foreign key is a column in one table that establishes a relationship with the primary key in another table. It links data across related tables, enabling the creation of meaningful associations between different pieces of information.
Indexes
Indexes are data structures that improve the efficiency of data retrieval operations. They provide quick access to rows based on values in one or more columns. Indexes are crucial for optimizing query performance in large databases.
Constraints
Constraints are rules defined on tables to enforce data integrity. Common constraints include ensuring values in a column are unique (UNIQUE constraint), requiring values to be non-null (NOT NULL constraint), and validating data against specific conditions (CHECK constraint).
Views
Views are virtual tables created from the results of queries. They simplify complex queries, present data in a user-friendly format, and can restrict access to specific columns or rows of a table. Views are particularly useful for data security and simplifying data retrieval.
Stored Procedures
Stored procedures are pre-defined SQL code blocks stored in the database. They encapsulate specific tasks, calculations, or data manipulations and can be reused in queries or application code, promoting code modularity and reusability.
Triggers
Triggers are special stored procedures that automatically execute in response to specific database events, such as data changes (INSERT, UPDATE, DELETE). They are used to enforce business rules, maintain data consistency, or log changes.
Transactions
Transactions are sequences of one or more SQL statements treated as a single unit of work. They ensure that a series of database operations either all succeed or all fail together. Transactions are essential for maintaining data consistency in multi-user database environments.
These elements collectively define the structure and functionality of a relational database, allowing data to be organized, stored, retrieved, and manipulated effectively and reliably.
Database Schema Design
Database Schema and Design
.schema: Command to view the schema of the database.Schema design involves structuring data efficiently to minimize redundancy and dependency by organizing it into separate tables.
Relationships
are established using keys, primarily the Primary Key and Foreign Key. These keys define how data in different tables is related to one another.
One-to-One: In a one-to-one relationship, one instance of an entity is related to only one instance of another entity. For example, one book is written by one author.
One-to-Many: In a one-to-many relationship, one instance of an entity can be related to multiple instances of another entity. For example, one author can write many books.
Many-to-Many: In a many-to-many relationship, multiple instances of one entity can be related to multiple instances of another entity. For example, many books can be written by many authors.
Entity-Relationship (ER) Diagram
ER diagrams are used to visualize and represent the relationships between different entities in a database.
Symbols used in ER diagrams:
"--o" represents a one-to-one relationship.
"--|" represents a one-to-many relationship.
"--< " represents a many-to-many relationship.
Normalization
Normalization is the process of breaking down large tables into smaller, related ones following a set of rules called normal forms.
The goal of normalization is to reduce data anomalies, ensure data integrity, and enhance database efficiency.
First Normal Form (1NF)
Ensures each column contains single, indivisible values and removes duplicate columns.
Second Normal Form (2NF)
Builds on 1NF and ensures that all non-key attributes are fully dependent on the primary key, avoiding partial dependencies.
Third Normal Form (3NF)
Extends 2NF by eliminating dependencies where non-key attributes depend on other non-key attributes, promoting simplicity.
Boyce-Codd Normal Form (BCNF)
Similar to 3NF but focuses on ensuring that every non-trivial dependency involves a candidate key.
Fourth Normal Form (4NF)
Addresses multi-valued dependencies, ensuring no sets of values can have multiple values for a single key.
Fifth Normal Form (5NF) or Project-Join Normal Form (PJNF)
Focuses on making sure a table can be reconstructed from smaller parts, especially in complex scenarios with multiple tables and joins.
These normal forms guide how to structure databases efficiently, reducing redundancy and maintaining data integrity. The choice of which normal form to apply depends on the specific needs of the database design.
De-normalization
Denormalization in databases and SQL involves intentionally introducing redundancy into a database schema to improve query performance. It's the opposite of normalization, which reduces data redundancy but can lead to complex and slow queries.
Denormalization techniques include merging tables, adding redundant columns, precomputing aggregates, and flattening hierarchies to make queries faster.
However, denormalization comes with trade-offs, including increased storage and potential data inconsistency, so it should be used carefully based on specific performance needs.
SQL conventions and concepts
Keyword Capitalization: SQL keywords like SELECT, FROM, WHERE, and others are typically written in uppercase for clarity and consistency.
Quoting Table and Column Names: Table and column names can be enclosed in double quotes ("column_name") to handle cases where they contain special characters or spaces.
String Representation: SQL strings are enclosed in single quotes ('string_variable') to distinguish them from other data types.
Subqueries: Subqueries are nested queries used to retrieve data that will serve as a condition or filter in the main query. For instance, you can use a subquery to find the ID of a publisher and then fetch books published by that specific publisher.
SQL command categories
DML (Data Manipulation Language)
DML commands are used to manipulate data stored in the database.
Common DML commands include:
DML commands are focused on managing the content of the database.
DDL (Data Definition Language)
DDL commands are used to define and manage the structure of the database.
Common DDL commands include:
DDL commands are used to define and modify the schema of the database.
DCL (Data Control Language)
DCL commands are used to control access to the data within the database.
Common DCL commands include:
GRANT: Gives specific permissions to database users or roles.
REVOKE: Removes permissions previously granted to users or roles.
DCL commands ensure data security and access control.
TCL (Transaction Control Language)
TCL commands are used to manage transactions within the database.
Common TCL commands include:
COMMIT: Saves changes made during the current transaction and makes them permanent.
ROLLBACK: Undoes changes made during the current transaction.
SAVEPOINT: Sets a point within a transaction to which you can later roll back.
SET TRANSACTION: Sets properties for a transaction.
TCL commands are crucial for maintaining data consistency and integrity during transactions.
DQL (Data Query Language)
DQL commands are used exclusively for querying and retrieving data from the database.
The primary DQL command is SELECT, which is used to retrieve data based on specified criteria.
Common SQL commands:
DQL commands are essential for extracting information from the database without modifying its structure or content.
These SQL command groups are used in various combinations to perform operations on relational databases. Understanding these categories helps database administrators, developers, and analysts work effectively with SQL to manage data and databases.
SQL Function categories
Scalar Functions
Operate on single values.
Return a single value.
Used for data manipulation within a single row or value.
Common scalar functions include string manipulation (e.g., UPPER(), CONCAT()), numeric operations (e.g., ROUND(), ABS()), date and time handling (e.g., GETDATE(), DATEADD()), conversion (e.g., CAST(), TO_DATE()), and mathematical calculations.
Aggregate Functions
Operate on sets of values.
Return a single value that summarizes data within a group of rows.
Typically used with the GROUP BY clause to perform calculations across multiple rows.
Common aggregate functions include SUM(), AVG(), COUNT(), MAX(), and MIN().
Used for summarizing data, such as finding totals, averages, counts, or extreme values within groups of rows.
Window Functions
Perform calculations across a set of related rows within a result set.
Do not reduce the number of rows returned; instead, they provide a way to analyze data in a window around each row.
Used with an OVER() clause to define the window specification.
Common window functions include ROW_NUMBER(), RANK(), DENSE_RANK(), LEAD(), and LAG().
Useful for tasks like ranking rows, accessing values from neighboring rows, and performing calculations over a sliding window of rows.
Aggregate functions like SUM() and AVG() can also be used as window functions to calculate values within specific windows.
Views
Create view
"CREATE VIEW" statement creates a virtual table defined by a query, which is stored in the database schema.
Essentially, it's like saving a query that gets re-executed every time you access it.
Views don't consume physical storage space.
Each time you query a view, it retrieves updated data from the underlying tables.
CREATE VIEW my_view AS
SELECT column1, column2
FROM my_table;Temporary View
You can create a temporary view that exists only for the duration of your connection to the database using "CREATE TEMPORARY VIEW."
Temporary views can also be based on other views.
CREATE TEMPORARY VIEW temp_view AS
SELECT *
FROM my_table
WHERE condition;Common Table Expressions (CTE)
CTEs are available for a single query and are defined using the "WITH" keyword.
They're a way to structure complex queries and make them more readable.
WITH my_cte AS (
SELECT column1, column2
FROM my_table
WHERE condition
)
SELECT * FROM my_cte;Partitioning
Views can be used to create queries for specific values (e.g., year, location) but cannot be modified themselves.
They are the result of combining data from other tables, not actual tables.
CREATE VIEW yearly_data AS
SELECT *
FROM my_table
WHERE year = 2023;Securing
Views can be used to control access to specific columns for different user groups (e.g., analysts).
"Anonymous" AS "column_name" can be used to indicate the presence of hidden columns.
In SQLite3, views won't prevent users from accessing the original tables, which is a limitation of SQLite3's security.
CREATE VIEW restricted_view AS
SELECT column1, column2, 'Anonnymous' as column3
FROM my_table;Triggers with Views
Views themselves cannot be modified, but you can modify the underlying tables.
You can create triggers to automatically modify tables when a user attempts to modify the view.
For example, you can use triggers to handle soft deletion when inserting into a view based on a table with a soft deletion option.
CREATE TRIGGER InsertWithSoftDeletion
INSTEAD OF INSERT ON SoftDeletedView
FOR EACH ROW
BEGIN
UPDATE OriginalTable
SET Deleted = 0
WHERE PrimaryKey = NEW.PrimaryKey;
END;Optimization
To measure query execution time
.timer on
-- Your SQL query here
.timer offThe query run time has three components:
real: Total elapsed time.user: CPU time spent in user mode.sys: CPU time spent in system (kernel) mode.
Index
A structure used to speed up the retrieval of rows from a table
Create an index:
CREATE INDEX name
ON table (column0, ...);Delete index:
DROP INDEX name;Indexes are automatically created when defining a primary key.
Query plans
Viewing query execution plan:
EXPLAIN QUERY PLAN
-- Your SQL query hereIf an index is used, it will be mentioned in the query plan.
If not, it will show a table scan (the default search method).
Covering index
An index in which queried data can be retrieved from the index itself
B-tree index
A B-tree index is a database indexing technique that organizes data in a tree-like structure separate from the main table.
This structure is divided into multiple nodes for efficient data retrieval and management.
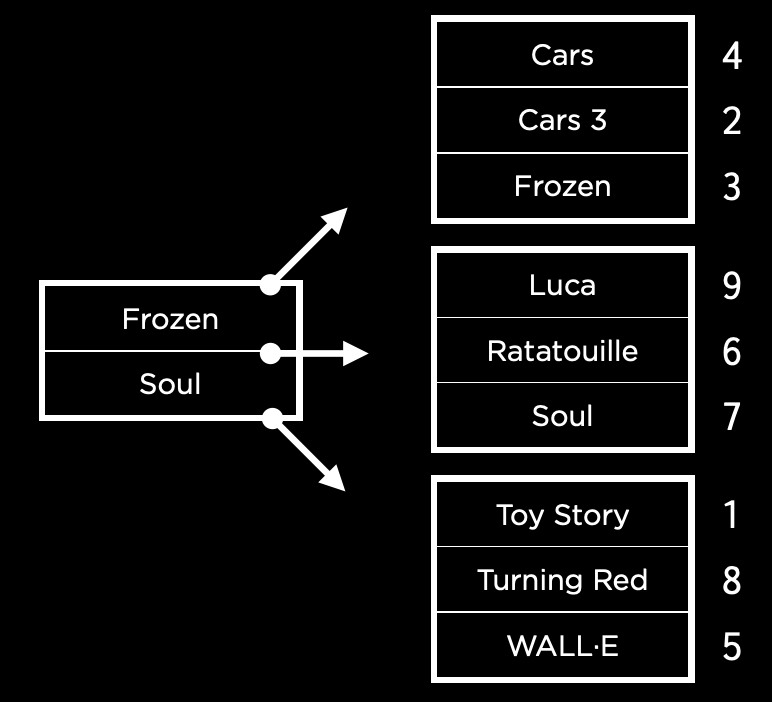
source: cs50 - Intro to Databases with SQL
drawback: takes up storage space
Partial index
CREATE INDEX name
ON table (column0, ...)
WHERE condition;Helps reduce storage consumption by indexing only a subset of rows.
Drawbacks of indexes
Storage Consumption: Indexes require additional storage space to store the index data structure. This can lead to increased storage costs, especially for large databases with numerous indexes.
Insertion Performance: The presence of indexes can slow down INSERT commands. When a new record is added to a table, the corresponding index(es) must also be updated, which can result in slower insertion times, particularly for tables with many indexes or frequent insertions.
Solutions:
Use partial indexes for frequently searched values.
Perform vacuuming to reclaim space and rebuild indexes.
VACUUM;Keep in mind that it can be resource-intensive, so it's best done during low database activity.
Concurrency
involves multiple transactions or processes accessing and modifying data simultaneously.
To ensure data integrity and consistency, we use transactions and adhere to the ACID properties:
Transaction - a unit of work in a database
BEGIN TRANSACTION; ... COMMIT; # or ROLLBACK; to cancel all the transaction stepsACID properties
Atomicity
A transaction is treated as a single, indivisible unit.
Either fully succeeds (commit) or fully fails (rollback).
Consistency
Guarantees that a transaction maintains data integrity, adhering to defined constraints.
Isolation
Transactions run as if they are sequential, preventing interference.
Prevents race conditions, ensuring program correctness.
Durability
Committed transaction changes are permanently saved, surviving system crashes or failures.
Race Conditions:
Occur when multiple processes access shared data concurrently, with outcomes depending on timing.
Can lead to data corruption and unexpected behavior.
Prevented by synchronization mechanisms (locks) to ensure exclusive data access.
Locks
Shared locks for reading data.
Exclusive locks for updating data.
Example of exclusive lock:
BEGIN EXCLUSIVE TRANSACTION; ... COMMIT;
Scaling
Scalability
Scalability refers to the ability to increase or decrease a system's capacity to meet changing demands. It's crucial for systems to handle increased workloads without compromising performance.
Embedded Database
SQLite is an example of an embedded database. It's self-contained and doesn't require a separate server process or dedicated hardware. It's often used in mobile apps, desktop software, and embedded systems.
Database Servers
Database servers are used when scalability is needed. They have dedicated hardware and software to efficiently manage and store data, making them suitable for larger applications and web services.
These servers can store data on both hard drives and RAM, allowing for faster querying and improved performance.
Examples of database servers include MySQL and PostgreSQL, which are widely used for managing data in web applications, enterprise systems, and more.
Scaling options
Vertical scaling
Increasing capacity by increasing a server’s computing power
Horizontal scaling
Increasing capacity by distributing load across multiple servers
Replication
Maintain copies of a database on multiple servers
Types: Single-Leader, Multi-Leader, Leaderless, …
only the leader replica can modify data.
read replica
a follower replica
a copy of a database for read-only access.
Communication
Synchronous (slower)
Asynchronous (prone to data corruption)
Sharding
distribution of the load among several servers
aims for balanced distribution to avoid overloads
susceptible to single points of failure
often used alongside replication strategies for better fault tolerance.
Access control
Create user on the server
CREATE USER user_name IDENTIFIED BY password; -- Grant accessBy default, these users do not have any access rights to the databases on the server.
Grant / revoke access (MySQL syntax)
GRANT privilege, ... TO user; REVOKE privilege, ... FROM user;Access types: ALL, CREATE, INSERT, SELECT, UPDATE, DELETE …
To grant the user permission to execute SELECT queries on the table:
GRANT SELECT ON `db_name`.`table_name` TO 'user';
SQL injection attack
SQL injection attacks involve inserting malicious SQL code into input fields or parameters of an application that interact with a database.
Attackers exploit vulnerabilities to manipulate SQL queries, potentially accessing sensitive data, modifying or deleting records, or executing administrative commands.
Prevention measures include using parameterized queries, input validation, and regular software updates.
Prepared statements (MySQL syntax)
PREPARE statement_name FROM 'sql_query'; SET @variable = value; EXECUTE statement_name USING @variable;are SQL queries that are precompiled by the database server and stored in a cache.
allows the server to efficiently execute the same query multiple times with different parameters without needing to re-parse and recompile the SQL each time.
handle escaping of special characters in parameters, reducing the risk of SQL injection attacks and enhancing security.
MySQL
MySQL is a popular open-source relational database management system used for storing and managing data on a server. It provides robust features for handling large datasets efficiently and is widely favored for its reliability, scalability, and ease of use in server environments.
Identifier Quoting
MySQL uses backticks (`) for quoting identifiers (table and column names).
Commands
-- Login
mysql -u [username] -h [hostname] -P [port] -p
-- Databases
SHOW DATABASES; -- list all databases on the server
CREATE DATABASE `db_name`; -- create a new database
USE `db_name`; -- connect to a specific database
-- Tables
SHOW TABLES; -- list all tables in the current database
DESCRIBE `table_name`; -- display the schema of a specific table
-- Table operations
ALTER TABLE table_name MODIFY column_name new_data_type; -- alter column
DELIMITER your_delimiter -- change delimiter
-- Logout
exit
quitAuto-Increment for Primary Key
In MySQL, when defining a primary key with auto-increment, you need to explicitly declare it using the
AUTO_INCREMENTkeyword. In SQLite and PostgreSQL, this auto-increment behavior is automated without a separate declaration.
Data Types
Integers
MySQL's integer types are sized based on the number of bytes used, allowing for more precise control. Examples include TINYINT (1 byte), SMALLINT (2 bytes), MEDIUMINT (3 bytes), INT (4 bytes), and BIGINT (8 bytes).
Strings
CHAR(m): Fixed-length character strings (m characters)
VARCHAR(m): Variable-length character strings. (0-m characters)
m value for CHAR and VARCHAR can be altered later, if needed
TEXT: For longer text data.
TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT
BLOB: For binary large objects.
ENUM(choice1, …): Stores one value from a predefined list.
SET(choice1, …): Stores zero or more values from a predefined set.
Date & Time
DATE: Used to store dates (YYYY-MM-DD).
TIME (fsp): Stores time values (HH:MM:SS).
DATETIME (fsp): Combines date and time (YYYY-MM-DD HH:MM:SS).
TIMESTAMP (fsp): Represents date and time, automatically updated when a record is inserted or updated.
YEAR: Stores year values (YYYY).
CURRENT_TIMESTAMP: Represents the current date and time.
Real numbers
FLOAT: A floating-point number with 4 bytes of storage.
DOUBLE PRECISION: A double-precision floating-point number with 8 bytes of storage.
Decimals
DECIMAL(M,D): Used for fixed-point decimal numbers, where:
M represents the total number of digits, including both the integer and decimal parts.
D represents the number of digits to the right of the decimal point (precision).
Stored procedure
is a collection of SQL commands saved in a database, allowing for complex operations, parameter passing, and code reuse. It enhances performance and security for database tasks.
When a stored procedure contains queries ending with semicolons, it's crucial to change the delimiter to prevent premature termination of the procedure. This ensures the entire procedure, up to the
ENDstatement, is recognized as a single block.Here's how to adjust the delimiter around the stored procedure definition:
delimiter //
CREATE PROCEDURE `collections`()
BEGIN
SELECT `title`, `accession_number`, `acquired`
FROM `collections` WHERE `deleted` = 0; -- Use semicolon within procedure
END //
delimiter ; -- Reset delimiter to semicolonStored procedures in SQL databases can accept input arguments, allowing dynamic execution based on the provided parameters. Here's a basic syntax for creating a stored procedure with an argument:
CREATE PROCEDURE `procedure_name`(IN arg TYPE) BEGIN ... -- Use `arg` within your SQL statements here END;They support conditional statements (
IF,ELSEIF,ELSE) and various types of loops (LOOP,REPEAT,WHILE), enabling complex logic and flow control within the database operations.To execute a stored procedure, use the
CALLcommand followed by the procedure name and any necessary arguments.
Stored procedures vs functions vs views
Stored Procedures: Execute multiple SQL statements, accept input/output parameters, can modify data, and are used for complex logic.
Functions: Return a single value, accept only input parameters, perform read-only operations, and are used for calculations within queries.
Views: Virtual tables created by a query to present data from one or more tables, do not accept parameters, and cannot modify data, simplifying data access and providing abstraction.
PostgreSQL
PostgreSQL is a powerful open-source relational database management system designed for server environments, offering advanced features for data storage, retrieval, and management. Renowned for its extensibility, reliability, and strong support for complex queries, PostgreSQL is a top choice for applications requiring robust database functionality.
Identifier Quoting
In PostgreSQL, double quotes (
") are used for quoting identifiers like table and column names, making them case-sensitive.Single quotes (
') are for string literals.
Commands
-- Login to postgres
psql postgresql://[user]:[password]@[host]:[port]/[database]
-- Working with Databases
\l -- list all databases on the server
CREATE DATABASE "db_name"; -- create a new database
\c "db_name" -- connect to a specific database
-- Managing Tables
\dt -- list all tables in the current database
\d "table_name" -- display the schema of a specific table
-- Logout of postgres
\qData types
Integers
SMALLINT: 2 bytes, range -32,768 to 32,767.
INT: 4 bytes, range -2,147,483,648 to 2,147,483,647.
BIGINT: 8 bytes, range -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807.
SMALLSERIAL: 2-byte autoincrement, range 1 to 32,767.
SERIAL: 4-byte autoincrement, range 1 to 2,147,483,647. Often used for primary keys
BIGSERIAL: 8-byte autoincrement, range 1 to 9,223,372,036,854,775,807.
Enumerated type
CREATE TYPE type_name AS ENUM ('choice1', 'choice2', ...);This creates a new data type that can only take one of the specified values, making it perfect for columns where only a specific set of options are valid.
Dates & Times
TIMESTAMP(p): Date and time with optional precision.
DATE: Only the date.
TIME(p): Only the time with optional precision.
INTERVAL(p): Time intervals with precision.
now(): Current date and time.
Real Numbers
MONEY: Currency amounts.
NUMERIC(precision, scale): Exact numeric values with specified precision and scale.
Other notes
Filtering Options: Equal Sign vs. IN Statement
the equal sign (
=) is used for exact single-value matching, while the "IN" statement is used for filtering based on multiple possible values or the outcome of a subquery. The choice between them depends on the specific filtering requirements of your SQL query.
Triggers:
Triggers are database objects that automatically respond to specific events or actions in the database.
These events can include INSERT, UPDATE, DELETE operations on tables.
Triggers are defined using the "CREATE TRIGGER" statement and can be executed either "AFTER" (e.g. insert or update a NEW row) or "BEFORE" (e.g. deleting an OLD row) a particular action.
Triggers are often used for purposes such as logging changes or enforcing data integrity rules.
CREATE TRIGGER name
AFTER <action on a table> ON table_name # or BEFORE
FOR EACH ROW
BEGIN
SQL command;
END;Soft Deletions:
Soft deletions are an alternative approach to handling deleted data in a database.
Instead of permanently removing rows, a "deleted" column is added to the table, typically with a default value of 0.
When a record is "soft deleted," its "deleted" column is updated to 1 to mark it as deleted.
Non-deleted rows can be accessed using a WHERE clause that filters out rows with a "deleted" value of 1.
Temporary tables and VIEWs can be used to manage and display data that was never deleted, making it easier to work with the non-deleted data effectively.
INSERT (populating the table)
To insert data into a table, you can use the "INSERT INTO" statement. It allows you to specify the target table and the values you want to insert into its columns.
It's essential to ensure that the values provided align with the column names and meet any constraints defined in the database schema.
For example, if a column has a NOT NULL constraint, you must provide a value for it during the insertion process.
In many relational database systems, such as SQLite, the primary key column can be omitted during insertion since it typically auto-increments.
INSERT INTO table_name (column_name0, ...)
VALUES
(value0, ...), # row 1
(value0, ...), # row 2
(value0, ...), # row 3
(value0, ...); # row 4SQLite's ".import" command is useful for importing data from files into database tables, but handling primary keys requires attention.
.import --<file type> --skip<number of rows> <from_file_name> <to_table_name>UPDATE
The "UPDATE" operation allows you to modify existing data in a database.
Using the "UPDATE" statement, you can specify the target table and set new values for one or more columns based on certain conditions.
It is useful for fixing data issues or making changes to existing records.
For example, you can apply functions like "TRIM()" to remove extra spaces from string columns or use "UPPER()" to convert text to uppercase.
UPDATE table
SET column0 = value0, ...
WHERE condition;DELETE
The "DELETE" operation is used to remove records or rows from a database table.
DELETE FROM table_name WHERE condition;Foreign key constraints should follow "ON DELETE" actions (SET NULL, SET DEFAULT, CASCADE) to avoid errors.
FOREIGN KEY ("column_name") REFERENCES table_name("column_name")
ON DELETE <action>CREATE TABLE
CREATE TABLE is used to create a new table in the database.
Syntax:
CREATE TABLE table_name (
column1 datatype1 [NULL | NOT NULL] [DEFAULT default_value] [column_constraint], );It specifies the table's structure, including column names, data types, constraints, and defaults.
Data Types and Storage Classes
Data types represent the kind of values a variable can hold.
Storage classes define how data is stored and retrieved in a database.
Common data types include INTEGER, REAL, TEXT, and BLOB.
Type affinities indicate the preferred storage class for a column's data type.
Table Constraints
Constraints define rules and conditions that apply to table columns.
Keys enforce uniqueness and integrity in columns.
PRIMARY KEY uniquely identifies each record in a table.
FOREIGN KEY establishes relationships between tables, ensuring referential integrity.
CHECK enforces specific conditions on column values.
DEFAULT specifies default values for columns.
NOT NULL ensures columns cannot contain NULL values.
UNIQUE restricts columns to have only unique values.
ALTER TABLE
ALTER TABLE is used to modify the structure of existing tables.
Commands include RENAME TO, ADD COLUMN, RENAME COLUMN, and DROP COLUMN.
Example:
ALTER TABLE "old_table_name" RENAME TO "new_table_name";These concepts are essential for creating and maintaining a well-structured database, ensuring data accuracy and efficiency.
JOIN
JOIN is used to combine rows from two or more tables based on a related column between them.
Types of JOIN:
INNER JOIN: Returns rows that have matching values in both tables.
OUTER JOIN: Returns matching rows and fills unmatched rows with NULL values.
LEFT JOIN: Prioritizes the rows from the left (first) table and includes all rows from it.
RIGHT JOIN: Prioritizes the rows from the right (second) table and includes all rows from it.
FULL JOIN: Includes all rows from both tables.
NATURAL JOIN: Automatically detects and performs an INNER JOIN on similar columns without an explicit ON condition.
SETS
SQL provides set operations to manipulate and combine data from different tables.
Common set operations include:
UNION: Combines all rows from two tables without duplicates.
INTERSECT: Selects rows present in both tables.
EXCEPT: Selects rows not present in both tables.
GROUP BY
GROUP BY is used to group query results based on the values in one or more columns.
It is often used in conjunction with aggregate functions like SUM, AVG, COUNT, etc.
Example: You can group books by the author's name to find the total number of books written by each author.
HAVING (aggregation)
HAVING is used to filter the results of a query that involves aggregate functions after the GROUP BY clause.
It specifies conditions for the groups formed by the GROUP BY clause.