Navigating Analytics Engineering: From dbt Setup to Data Visualization
DE ZoomCamp course: Module 4

Explore the fundamentals of analytics engineering with guidance from DE ZoomCamp 2024 and dbt documentation. Learn to set up dbt with BigQuery, deploy models, and use visualization tools like Google Data Studio and Metabase. Discover key concepts such as ETL vs. ELT and Dimensional Modeling, designed to boost your data analytics skills. This concise guide provides a clear path for anyone aiming to enhance their analytics engineering knowledge for practical, impactful insights.
Source:
Contents:
dbt setup for using BigQuery
create a new GCP service account
use BigQuery API with access to application data
give the account any name (e.g. dbt_service_account)
give the account BigQuery admin role
get new service account key in JSON format
Cloud
setup a new dbt cloud project
name your project
set up BigQuery connection
clone your GitHub repo using SSH keys
paste SSH key from your GH repo in dbt cloud
deploy result keys in your GH repo settings
Local
setup a new dbt core project
install required dbt packages to your machine
install both dbt-core and dbt-bigquery adapter
pip install dbt-bigquery
set up connection details
in your root directory create a .dbt directory create a
profiles.ymlfile<profile-name>: target: <target-name> # this is the default target outputs: <target-name>: type: <bigquery | postgres | redshift | snowflake | other> schema: <schema_identifier> threads: <natural_number> ### database-specific connection details ... <target-name>: # additional targets ... <profile-name>: # additional profiles ...
create your first project
in the directory for your dbt project run
dbt initThis will create a directory for your first project
Enter your project folder and check for connection
dbt debug
set up
dbt_project.ymlyou can create the name for your project. Make sure to change the name in models section as well.
check profile section - should be the same as in
profiles.ymlfile.
Analytics Engineering concepts
Data Team Roles
Data Engineer: Responsible for preparing and maintaining the infrastructure required by the data team.
Analytics Engineer: Brings good software engineering practices into the efforts of data analysts and data scientists.
Data Analyst: Utilizes data to respond to inquiries and address challenges.
Analytics Engineer Tools
Data Loading: Tools and processes focused on importing, cleaning, and preprocessing data.
Data Storing: Utilizes cloud-based data warehouses such as Snowflake, BigQuery, and Redshift for efficient data storage and management.
Data Modeling: Employs tools like dbt (data build tool) or Dataform for structuring and organizing data in a useful format.
Data Presentation: Leverages Business Intelligence (BI) tools such as Google Data Studio, Looker, Mode, and Tableau for visualizing data and sharing insights.
ETL vs ELT
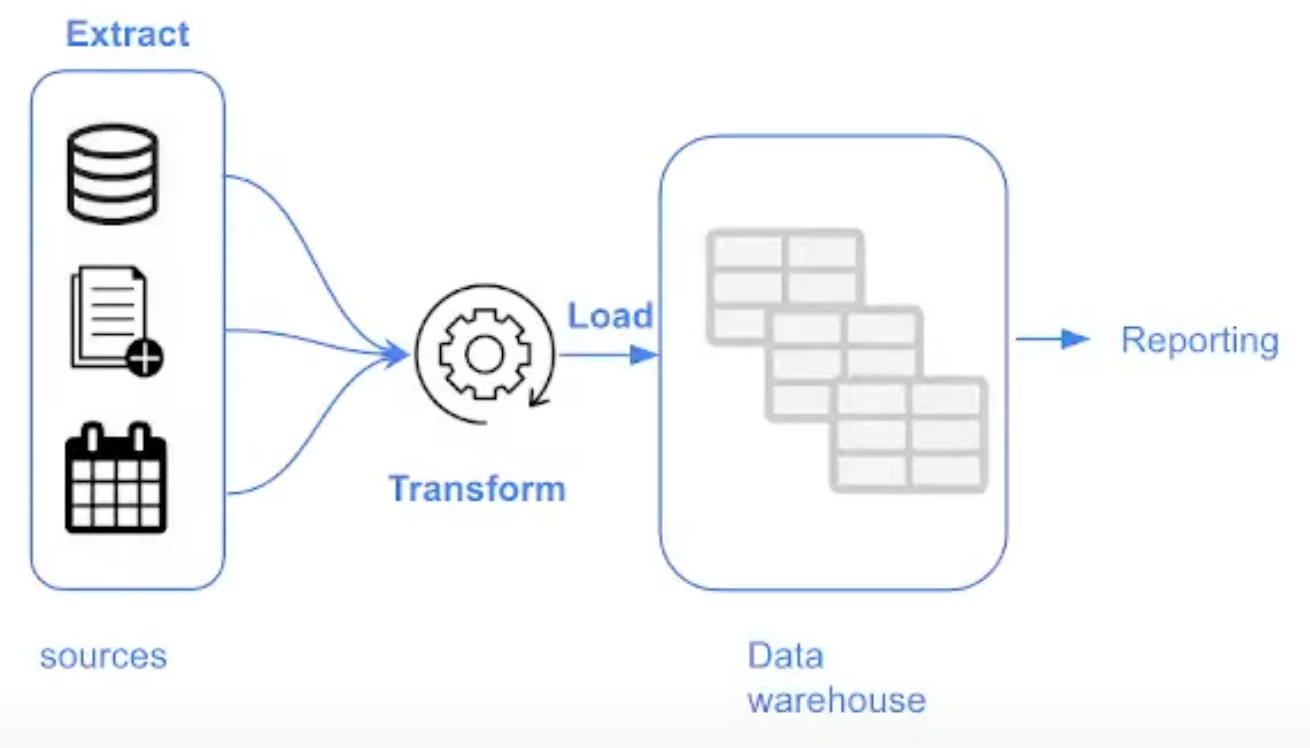
ETL (Extract, Transform, Load)
Provides a more stable and compliant environment for data analysis.
Incurs higher storage and compute costs due to the processing required before data is loaded into the warehouse.
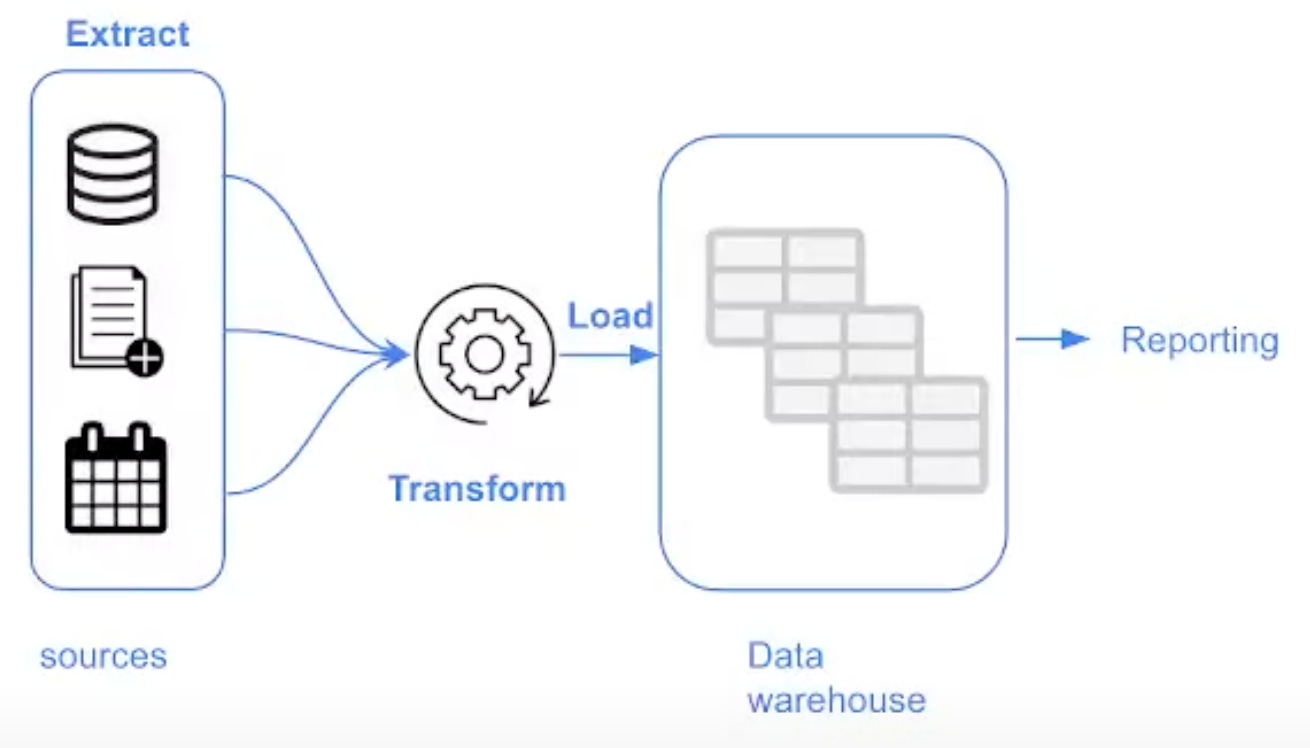
ELT (Extract, Load, Transform)
Offers faster and more flexible data analysis by loading data into the warehouse before transforming it.
Results in lower costs and reduced maintenance compared to ETL, as data transformation is handled within the data warehouse.

Kimball’s Dimensional Modeling (DM)
Objective
To make data understandable for business users.
To ensure fast query performance.
Approach
Focuses on user understandability and query performance, prioritizing these over non-redundant data (3NF - Third Normal Form).
Other Approaches
Bill Inmon's methodology.
Data Vault modeling.
Elements of DM
Fact Tables
Contain measurements, metrics, or facts.
Correspond to a business process.
Represented by "verbs."
Dimension Tables
Correspond to a business entity.
Provide context to the business.
Represented by "nouns."

DM architecture
Staging Area (Bronze Layer)
Houses raw data.
Not designed for broad accessibility.
Processing Area (Silver Layer)
Transforms raw data into structured data models.
Concentrates on efficiency and standardization.
Presentation Area (Gold Layer)
Delivers the final data presentation.
Tailored for business stakeholders' consumption.
dbt (data build tool)
dbt is a SQL-based transformation tool that streamlines analytics code deployment in data warehouses, emphasizing modularity, CI/CD, and documentation.
It enables complex data transformations directly within the data warehouse (ELT), supporting version control, testing, and streamlined workflow sharing.

How does dbt work
Define transformations: Users write SQL queries to define transformations, which are stored as dbt models.
Run models: dbt compiles these SQL models and runs them in the data warehouse, transforming raw data into structured formats.
Version control: Models are managed in version control, facilitating collaboration and tracking changes.
Testing and documentation: dbt supports automated testing and documentation of data models, ensuring data quality and ease of use


dbt deployment
dbt Core (local):
Open-source, command-line tool.
Manual setup and execution.
User-managed infrastructure.
Compatible with databases like Postgres and others.
dbt Cloud:
Managed SaaS platform.
Web interface with scheduling and permissions.
Includes IDE, CI/CD pipelines, and support.
Free and paid tiers available.
Supports BigQuery, Postgres, etc..

dbt model
A dbt model is a SQL file with configurations and transformations that structure raw data for analysis. Here’s a concise overview of its components:
Configuration Header
Defines model settings like materialization (e.g., table, view) using Jinja templating.
{{ config(materialized='table') }}Documentation (Optional)
Comments describing the model's purpose, author, and creation date for better maintainability.
Jinja Templating
Injects logic, variables, and references to other models for dynamic SQL generation.
SELECT * FROM {{ ref('raw_data') }}SQL Transformation Logic
The SQL code applying the data transformation, potentially using CTEs for complex logic.
Dependencies
Defined by ref() functions, indicating relationships between models for execution order.
Materialization Strategies
Determines how dbt materializes the output (as a view, table, incremental, or ephemeral).

This streamlined structure facilitates efficient and organized data transformation, making dbt models crucial for scalable analytics engineering.
dbt concepts
Macros
Utilize control structures (e.g., if statements, for loops) in SQL.
Leverage environment variables for production deployments.
Generate queries based on the results of other queries.
Abstract SQL snippets into reusable macros, akin to functions in programming languages.
To create in macros folder create an sql file and use the following template:
{# Description of what the macro does #} {% macro unnamed_macro(argument1, argument2) -%} # Macro logic here {%- endmacro %}To call the macros use the following template in the model sql
{{ name_of_the_macro(argument) }}
Ref Macro
Used to reference underlying tables and views in the data warehouse.
Enables running the same code across different environments, resolving schema automatically.
Dependencies are automatically built based on references.
Example:
select
column1,
column2
from {{ ref('table_or_view_name') }}FROM clause
Sources
The data loaded to our DWH that we use as sources for our models
Configuration defined in the yml files in the models folder
version: 2sources: - name: source_name database: your_database schema: your_schema tables: - name: table_name freshness: error_after: {count: 6, period: hour}Used with the source macro that will resolve the name to the right schema, plus build the dependencies automatically
Source freshness can be defined and tested
Seeds
CSV files stored in the project repository under the seed folder.
version: 2seeds: - name: seed_name schema: your_schema table_name: table_name filename: path/to/seed.csvBenefits from version control for tracking changes.
Equivalent to a COPY command in database terms.
Recommended for static or infrequently changing data.
Executed using dbt seed -s file_name command, where file_name is the name of the seed file.
Packages
Similar to libraries in other programming languages, containing models and macros for specific areas.
Standalone dbt projects that integrate into your own project via
packages.yml.packages: - package: <publisher>/<package_name> version: <version>Imported with
dbt deps.Available on the dbt Package Hub.
To call a function from a package in the dbt model use the following template:
{{ package_name.function_name( arg1 = 'value1', arg2 = 'value2', ... ) }}
Variables
Enable defining project-wide values.
Utilized with
{{ var('...') }}for data provision in models.Defined in:
dbt_project.ymlfile.vars: my_variable: value another_variable: another_valueCommand line
dbt run --vars 'my_variable: value, another_variable: another_value'
Tests
Assumptions about data:
Tests in dbt are SQL queries.
These assumptions compile to SQL, revealing failing records.
Tests are defined in the
schema.ymlfile.
Basic tests provided by dbt:
Uniqueness
Null values
Accepted values
Foreign key relations
Custom tests can be created using queries.
version: 2 models: - name: my_model_name description: > This model represents [description of the model]. tests: - unique: columns: [column_name] severity: error - not_null: columns: [column_name] severity: error - accepted_values: column: column_name values: [value_1, value_2, value_3] severity: warning - foreign_key: columns: [column_name] table: referenced_table_name to: referenced_column_name severity: error
Documentation
dbt offers documentation generation for projects, rendered as a website in
schema.ymlfile .Includes project details:
Model code (from .sql files and compiled)
Model dependencies
Sources
Auto-generated Directed Acyclic Graph (DAG) from ref and source macros
Descriptions (from .yml files) and tests
Provides information about the data warehouse (information_schema):
Column names and data types
Table statistics such as size and rows
dbt docs can be hosted in dbt Cloud.
models: - name: my_model_name description: > Description of my_model_name. - name: another_model_name description: > Description of another_model_name.
Model deployment
Model Deployment: Process involves moving models from development to production environments.
Separation: Development allows building and testing models without impacting production.
Environment Differences: Deployment typically uses a distinct schema in the data warehouse and different user accounts.
Workflow:
Develop models in a user-specific branch.
Open a Pull Request (PR) to merge changes into the main branch.
Merge the branch into the main branch.
Execute new models in production using the main branch.
Schedule models for regular operation.

Running a dbt model into production
dbt Cloud Scheduler: Used to create jobs for production runs.
Job Commands: A single job can execute multiple commands.
Triggering Jobs: Can be initiated manually or scheduled.
Logging: Each job maintains a log of its runs, with individual command logs.
Documentation: Jobs can generate documentation accessible under run details.
Source Freshness: If run, results are viewable post-job completion.
Continuous integration
Continuous Integration (CI): Regular merging of development branches into a central repo, followed by automated builds and tests.
Goal: Minimize bugs in production code, maintain project stability.
dbt CI Integration: Enables CI on pull requests through webhooks from GitHub or GitLab.
Webhooks: Trigger a new dbt Cloud job run upon PR readiness.
Temporary Schema: CI job runs use a temporary schema.
Merge Conditions: PRs can only be merged after successful job completion.
Steps to deploy the model (via dbt cloud IDE)
Push Changes: Upload all modifications to the GitHub repository.
Deployment Environment: Establish a new environment targeting the BigQuery dataset.
Job Creation: Initiate a job within the configured environment.
Execution Settings: Specify commands for the job's execution.
Triggers: Configure job triggers for automated execution.
dbt commands
dbt run: Executes all models within the dbt project.dbt build: Executes all models and seeds in the dbt project.dbt build --select <model_name>: Executes only the specified model.dbt build --select +<model_name>: Executes the specified model and all other dependent models.
Data visualization
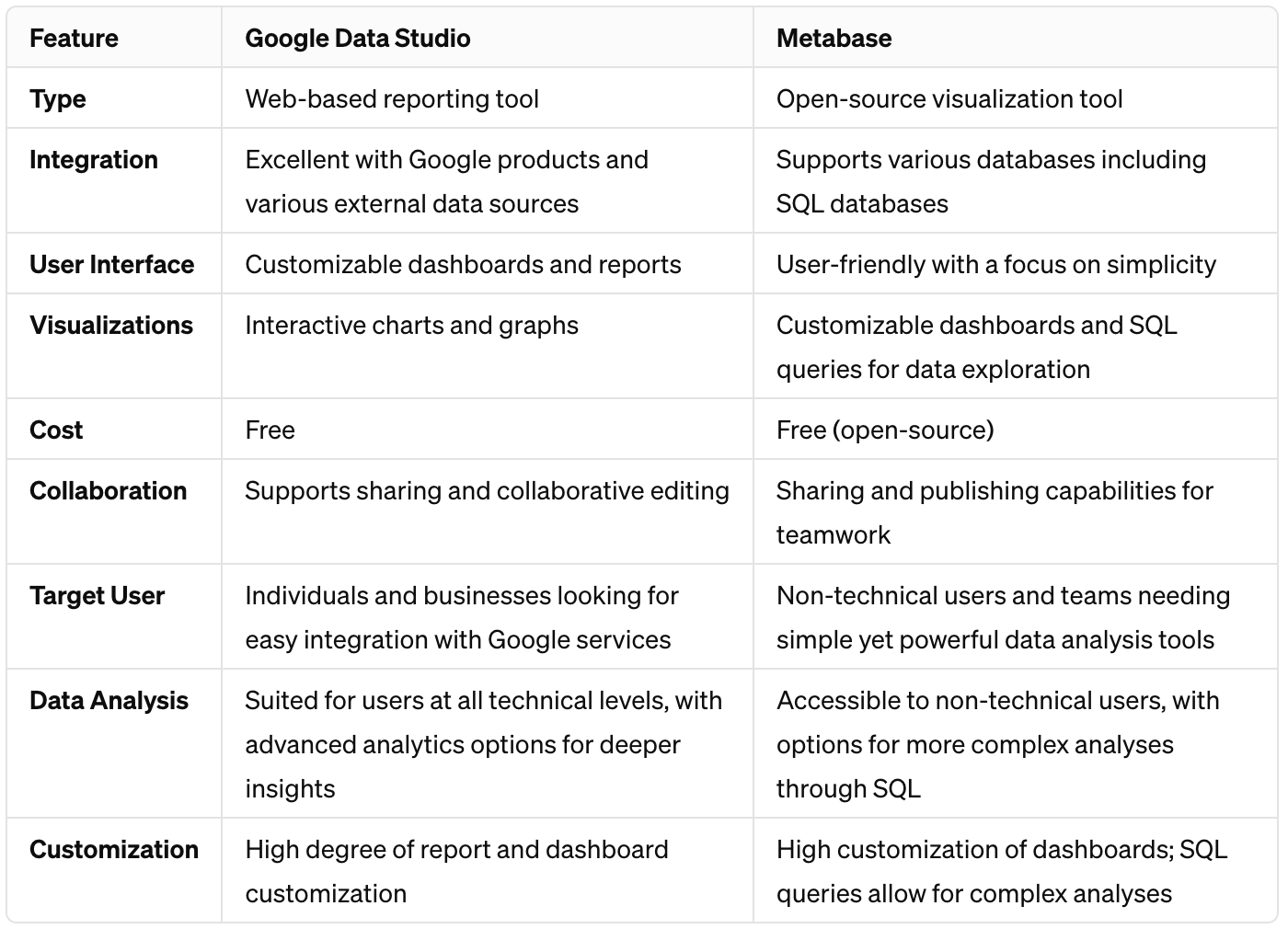
Google Data Studio (cloud)
Web-based Reporting Tool: Allows for the creation of customizable dashboards and reports.
Integration: Offers seamless integration with other Google products and various external data sources.
Interactive Visualizations: Enables users to create interactive charts and graphs.
Collaboration: Supports sharing and collaborative editing of reports and dashboards.
Free to Use: Available at no cost, making it accessible for individuals and businesses.
Metabase (local)
Open-Source: A free tool for creating visualizations and dashboards from your data.
User-Friendly: Designed with a focus on simplicity, making data analysis accessible to non-technical users.
Flexible Data Sources: Connects to a variety of databases and SQL databases without requiring in-depth SQL knowledge.
Customization: Offers customizable dashboards and the ability to write SQL queries for complex data exploration.
Collaboration Features: Includes sharing and publishing capabilities to enhance teamwork.