
BigQuery datasets: Tables

BigQuery tables are key to Google's serverless data warehouse, enabling efficient data storage, access, and analysis. This guide covers the essentials of BigQuery table management, including creation, access control, and leveraging advanced features like external tables. It provides a concise overview for effectively utilizing BigQuery for data analysis and management.
Sources:
Contents:
BigQuery tables
BigQuery standard tables store structured data in a columnar format, including:
Tables: These have a defined schema with typed columns.
Table Clones: Writable, lightweight copies storing only changes from the base table.
Table Snapshots: Read-only, point-in-time copies, storing differences from the base table, allowing restoration.
Limitations:
Table names must be unique per dataset.
When you export BigQuery table data, the only supported destination is Cloud Storage.
When you use an API call, enumeration performance slows as you approach 50,000 tables in a dataset.
The Google Cloud console can display up to 50,000 tables for each dataset.
Table naming:
Unique per dataset, up to 1,024 UTF-8 bytes.
Can include Unicode characters in certain categories.
Examples: table 01, ग्राहक, 00_お客様, étudiant-01.
Caveats:
Case-sensitive by default.
Some names are reserved; choose a different name if an error occurs.
Duplicate dot operators are implicitly removed.
Example:
Before: project_name....dataset_name..table_name
After: project_name.dataset_name.table_name
Create and use tables:
Create an empty table
CREATE TABLE `myproject.mydataset.newtable` ( column1_name datatype [OPTIONS], column2_name datatype [OPTIONS], ... ) OPTIONS ( expiration_timestamp = TIMESTAMP 'YYYY-MM-DD HH:MM:SS UTC', description = 'Description of the table', labels = [('label1_key', 'label1_value'), ('label2_key', 'label2_value')] );In BigQuery, options provide additional settings or metadata for tables. Here's a concise explanation of the options used in the provided template:
expiration_timestamp: Sets a timestamp for table expiration.description: Provides a brief description of the table.labels: Assigns metadata labels to the table for organization.
Create a table from a query result
CREATE TABLE `myproject.mydataset.new_table` AS ( SELECT column1_name, column2_name, ... FROM dataset_name.table_name );For more information see the official documentation
Access to the tables
Access control in BigQuery involves granting IAM roles to entities at different levels of the Google Cloud resource hierarchy, such as project, folder, or organization, as well as at the dataset or table/view level.
Levels of access control:
High level in the resource hierarchy (e.g., project): Provides broad access to multiple datasets.
Dataset level: Specifies operations allowed on tables/views within a specific dataset.
Table/view level: Specifies operations allowed on individual tables/views.
Access is additive: Granting access at a lower level overrides lack of access at higher levels.
Methods for restricting data access within tables:
Column-level security
Column data masking
Row-level security
Custom IAM roles can be created to tailor permissions for specific operations.
It's not possible to set "deny" permissions on resources protected by IAM.
For more information see the official documentation
Get information about tables
INFORMATION_SCHEMAis a series of views that provide access to metadata about datasets, routines, tables, views, jobs, reservations, and streaming data.You can query the following views to get table information:
Use the
INFORMATION_SCHEMA.TABLESandINFORMATION_SCHEMA.TABLE_OPTIONSviews to retrieve metadata about tables and views in a project.Use the
INFORMATION_SCHEMA.COLUMNSandINFORMATION_SCHEMA.COLUMN_FIELD_PATHSviews to retrieve metadata about the columns (fields) in a table.Use the
INFORMATION_SCHEMA.TABLE_STORAGEviews to retrieve metadata about current and historical storage usage by a table.
For more information see the official documentation
Specify table schemas
Schema components
Column names (required)
BigQuery column names must start with a letter or underscore, can include letters, numbers, and underscores, are capped at 300 characters, and cannot use reserved prefixes. Duplicate names with different cases are not permitted. Flexible naming extends character support for diverse languages and symbols.
Column descriptions (optional)
Each column can include an optional description. The description is a string with a maximum length of 1,024 characters.
Default values (optional)
The default value for a column must be a literal or one of the following functions:
CURRENT_DATE
CURRENT_DATETIME
CURRENT_TIME
CURRENT_TIMESTAMP
GENERATE_UUID
RAND
SESSION_USER
ST_GEOGPOINT
GoogleSQL Data Types (required)
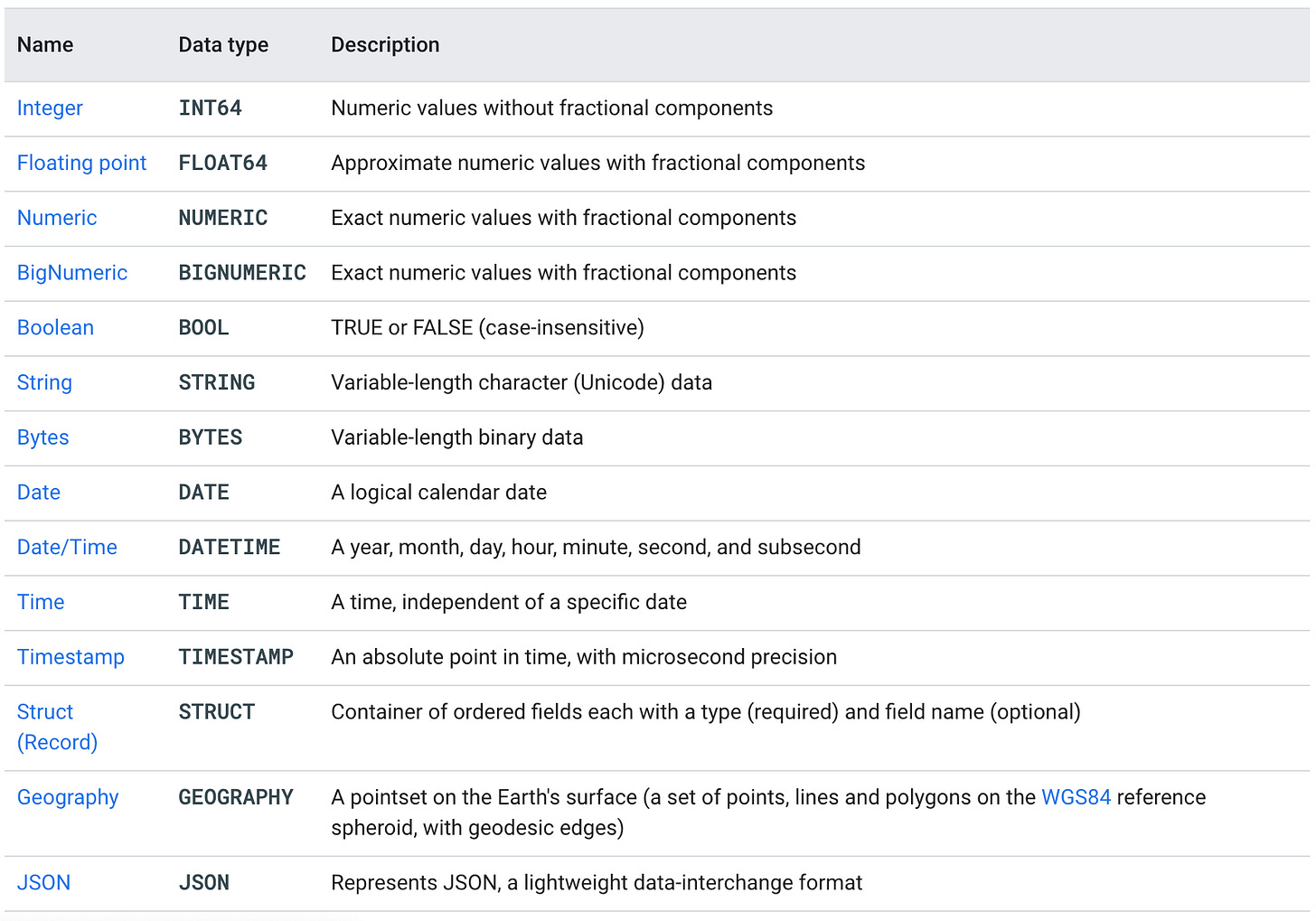
Modes (optional)

Mode is optional. If the mode is unspecified, the column defaults to
NULLABLE.
Rounding mode (optional)
For NUMERIC or BIGNUMERIC columns in BigQuery, you can specify
rounding_modeto control how values are rounded:ROUND_HALF_AWAY_FROM_ZERO (default) rounds away from zero,
ROUND_HALF_EVEN rounds towards the nearest even number.
This option isn't available for other data types.
Specify the schema
CREATE TABLE IF NOT EXISTS mydataset.newtable (x INT64, y STRING, z BOOL) OPTIONS( description = 'My example table');Specifying a schema in the API
To define a table schema via API in BigQuery, use
jobs.insertfor loading data with a schema ortables.insertto create a table with a schema. Configure the schema in the respective resource properties.
For more information see the official documentation
Schema of table with nested and repeated columns
Nested columns in BigQuery are defined using the RECORD data type, acting like a STRUCT to contain ordered fields.
Repeated columns are set with the mode REPEATED, functioning as an ARRAY.
A RECORD can be repeated, representing an array of STRUCTs, and a RECORD's field can also be repeated, shown as a STRUCT containing an ARRAY. However, directly nesting arrays within each other is not allowed.
Note the limitations: no more than 15 levels of nested RECORD types and RECORD is incompatible with certain SQL operations.
Create table (repeated and nested)
CREATE TABLE IF NOT EXISTS dataset_name.table_name ( simple_field_name SIMPLE_DATA_TYPE, repeated_struct_field_name ARRAY< STRUCT< nested_field_name DATA_TYPE, ... > >, ... ) OPTIONS ( description = 'Your table description' ... );
Insert table (repeated and nested)
INSERT INTO dataset_name.table_name (column1, column2, ..., complex_column) VALUES (value1, value2, ..., ARRAY< STRUCT< nested_field1, nested_field2, ... > > ([("nested_value1", "nested_value2", ...)]));OR
INSERT INTO dataset_name.table_name (column1, column2, ..., complex_column) VALUES ( "value1", "value2", ... [("nested_value1", "nested_value2", ...)] );
Query table (repeated and nested)
SELECT column1, column2, complex_column[offset(0)].nested_field FROM dataset_name.table_name;
Deduplicate duplicate records in a table
CREATE OR REPLACE TABLE dataset_name.table_name AS ( SELECT * EXCEPT(row_num) FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY deduplicate_columns ORDER BY order_column) AS row_num FROM dataset_name.table_name ) AS temp_table WHERE row_num = 1 );
Schema auto-detection
Schema auto-detection in BigQuery allows for automatic schema inference for CSV, JSON, and Google Sheets during data loading or querying external sources. It scans a sample of data to determine data types for each column.
For self-describing formats like Avro, Parquet, ORC, Firestore, and Datastore exports, BigQuery automatically infers schemas without needing to enable auto-detection.
However, you can manually provide a schema for these formats if desired.
Detected schemas can be viewed in the Google Cloud console or using the `bq show` command.
For more information see the official documentation
Modify table schemas
Most schema modifications can be done using SQL data definition language (DDL) statements, which are free of charge.
To modify a table schema, you can export the table data to Cloud Storage, then load it into a new table with the modified schema. While BigQuery load and export jobs are free, there are costs for storing exported data in Cloud Storage.
Note: Immediate schema changes might not be reflected in INFORMATION_SCHEMA views. Use the tables.get method for immediate updates.
For more information see the official documentation
BigQuery’s tables also support table partition and table clustering, discussed separately

External Tables
External data sources allow direct querying in BigQuery, even if the data resides outside BigQuery storage. For instance, data might be stored in another Google Cloud database, Cloud Storage files, or a different cloud service. This setup enables analysis in BigQuery without migration.
Use cases for external data sources include:
Streamlining extract-load-transform (ELT) workflows by loading and cleansing data in one step, then saving the cleaned result to BigQuery storage using a CREATE TABLE ... AS SELECT query.
Joining BigQuery tables with frequently updated data from external sources. Querying directly avoids reloading data into BigQuery storage for each change.
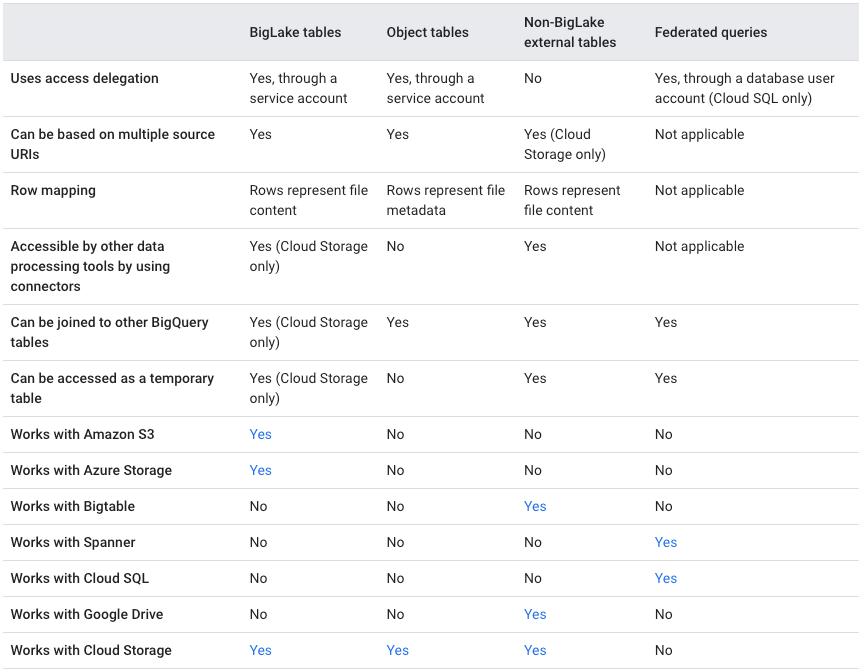
BigQuery offers two mechanisms for querying external data: external tables and federated queries.
External tables in BigQuery point to data stored outside BigQuery, including:
BigLake tables: Target structured data in services like Cloud Storage, Amazon S3, and Azure Blob Storage, with a focus on enforcing detailed security at the table level.
Object tables: Link to unstructured data in Cloud Storage, with security considerations for accessing such data.
Non-BigLake external tables: Connect to structured data in Cloud Storage, Google Drive, and Bigtable, lacking the advanced security features of BigLake tables.
Federated queries enable sending query statements to Spanner or Cloud SQL databases and receiving the results as a temporary table. Leveraging the BigQuery Connection API, federated queries establish connections with Spanner or Cloud SQL. By employing the EXTERNAL_QUERY function in your query, you can transmit a query statement to the external database using its SQL dialect. The results are then converted to GoogleSQL data types.
External data source feature comparison
For more information see the official documentation